
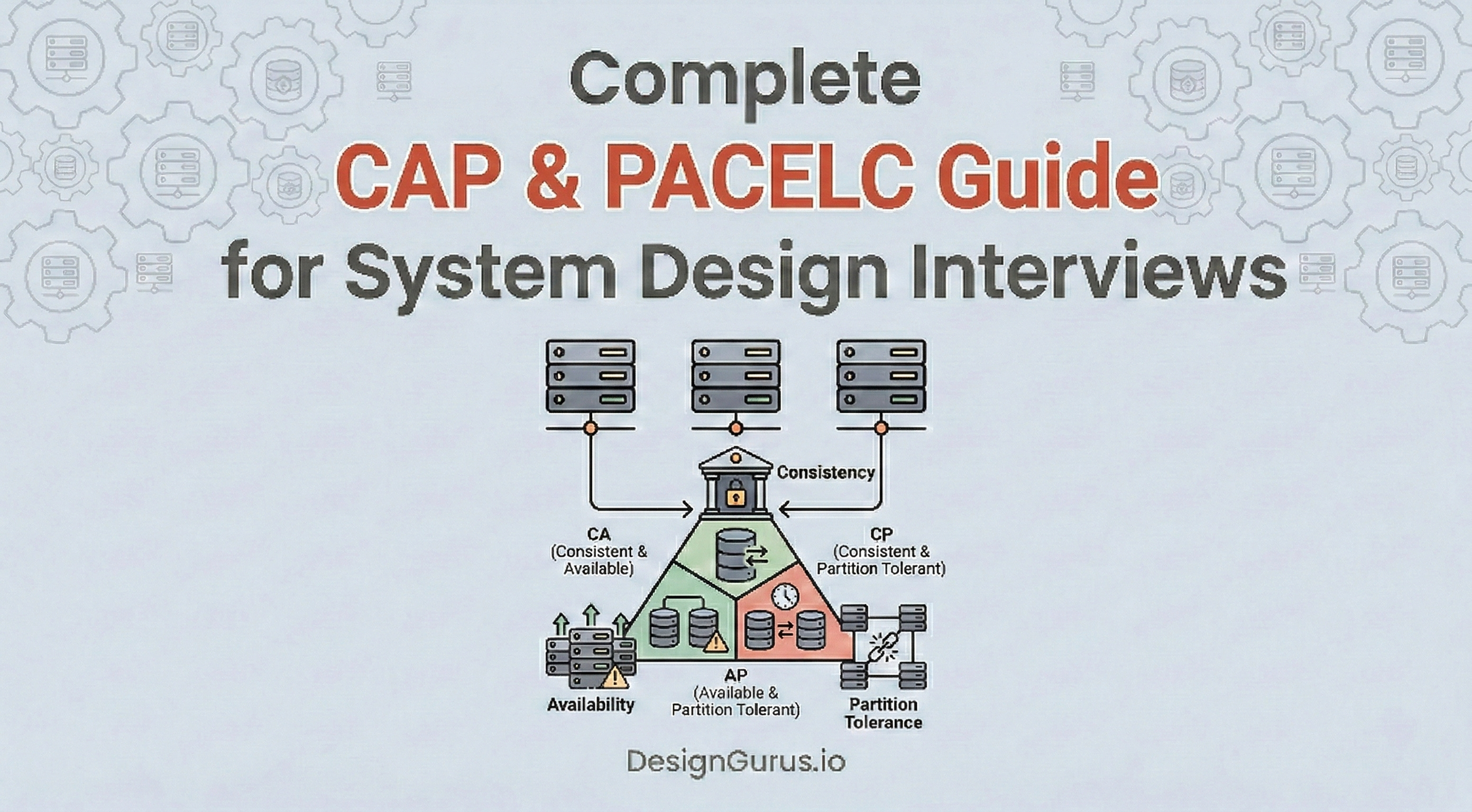
Complete CAP & PACELC Guide for System Design Interviews [2026 Edition]
A complete guide for software engineers on the CAP theorem and PACELC theorem. Understand data replication and strict network partition tradeoffs.

Building scalable software architecture requires storing massive amounts of digital information reliably.
A standard application typically begins with a single central database server handling all operations.
This centralized approach works perfectly when incoming data traffic remains low. However, a single central server possesses strict physical limitations regarding computational power and memory space.
When data traffic increases massively, a single processing unit becomes completely overwhelmed and crashes. To prevent complete application downtime, engineers must distribute the storage workload across multiple connected computers.
This group of connected computers forms a distributed system. Distributing the workload solves the computational bottleneck immediately while ensuring continuous operation.
However, moving from one central server to multiple connected servers introduces a severe synchronization problem. These individual computers must communicate constantly over physical network cables to share new data.
Physical network cables and routing switches are inherently unreliable components. When these communication links break, the distributed system must make a critical decision regarding how to process incoming information.
The software must either stop accepting new data to maintain perfect accuracy across all computers, or it must keep accepting data and risk creating mismatched records. This fundamental technical dilemma dictates how all modern distributed applications operate behind the scenes. Understanding how to navigate these strict mathematical constraints is critical for building resilient architecture.
The Shift to Distributed Architecture
A central database server processes every incoming read and write request.
As the client application grows, the volume of these requests multiplies exponentially. The central processing unit within the server eventually reaches maximum physical capacity. When this capacity is breached, the server responds slowly or crashes entirely.
Upgrading the physical components of a single server is called vertical scaling. Engineers can add more memory and faster processors to delay the inevitable crash. However, vertical scaling has a strict physical ceiling. A single motherboard can only hold a specific amount of hardware components.
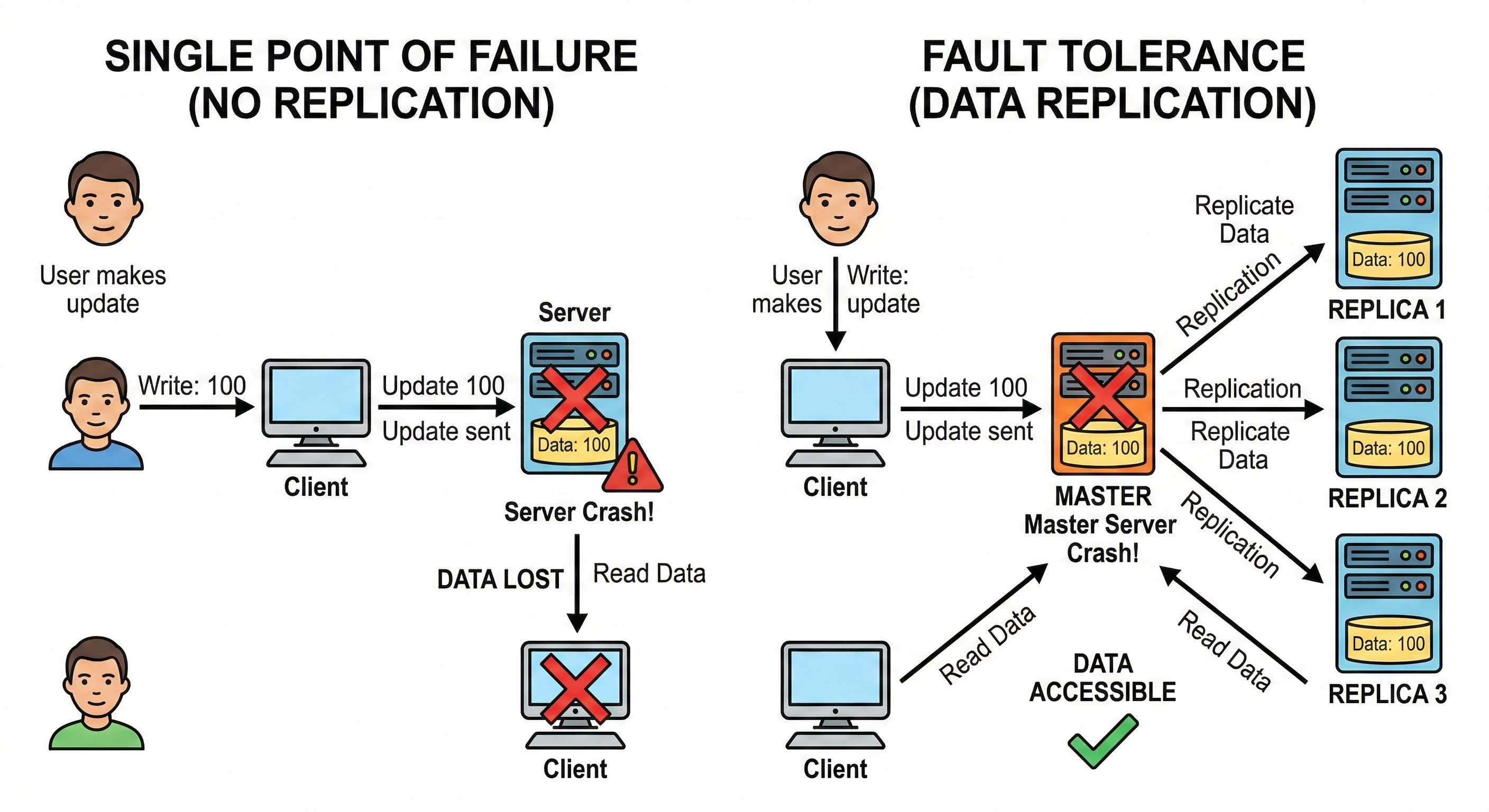
Furthermore, relying on a single server creates a dangerous single point of failure.
If the internal hard drive corrupts, all stored data is permanently lost. The entire client application goes offline until the server is physically repaired or replaced.
To avoid this catastrophic downtime, the software architecture must evolve.
Distributing the Workload
To bypass the limitations of vertical scaling, engineers utilize horizontal scaling.
Horizontal scaling involves adding completely separate computers to the infrastructure. These separate computers work together to handle the massive volume of incoming requests.
In a distributed database architecture, these individual computers are called nodes.
A collection of connected nodes forms a database cluster.
To the external client application, the cluster appears as one single massive database. Behind the scenes, the cluster is actively routing traffic to different individual nodes.
By routing traffic to multiple nodes, the system balances the computational workload perfectly. No single node becomes overwhelmed by incoming requests. If one node experiences a hardware failure, the client application simply connects to a different surviving node.
This eliminates the single point of failure completely.
The Hidden Cost of Replication
While horizontal scaling solves processing bottlenecks, it introduces a severe data management problem. When a client application saves a new data record, the request initially hits only one specific node.
That specific node must now share the new data with every other node in the cluster.
This constant sharing of information is known as data replication.
Data replication ensures that every node holds an exact copy of the entire database.
If a node crashes, the data remains safely stored on the other functional nodes.
However, data replication requires nodes to send messages over physical network cables. These data packets must travel through routers and network switches to reach their destination. This physical travel takes measurable time and introduces a massive dependency on absolute network reliability.
Understanding the Network Failure Problem
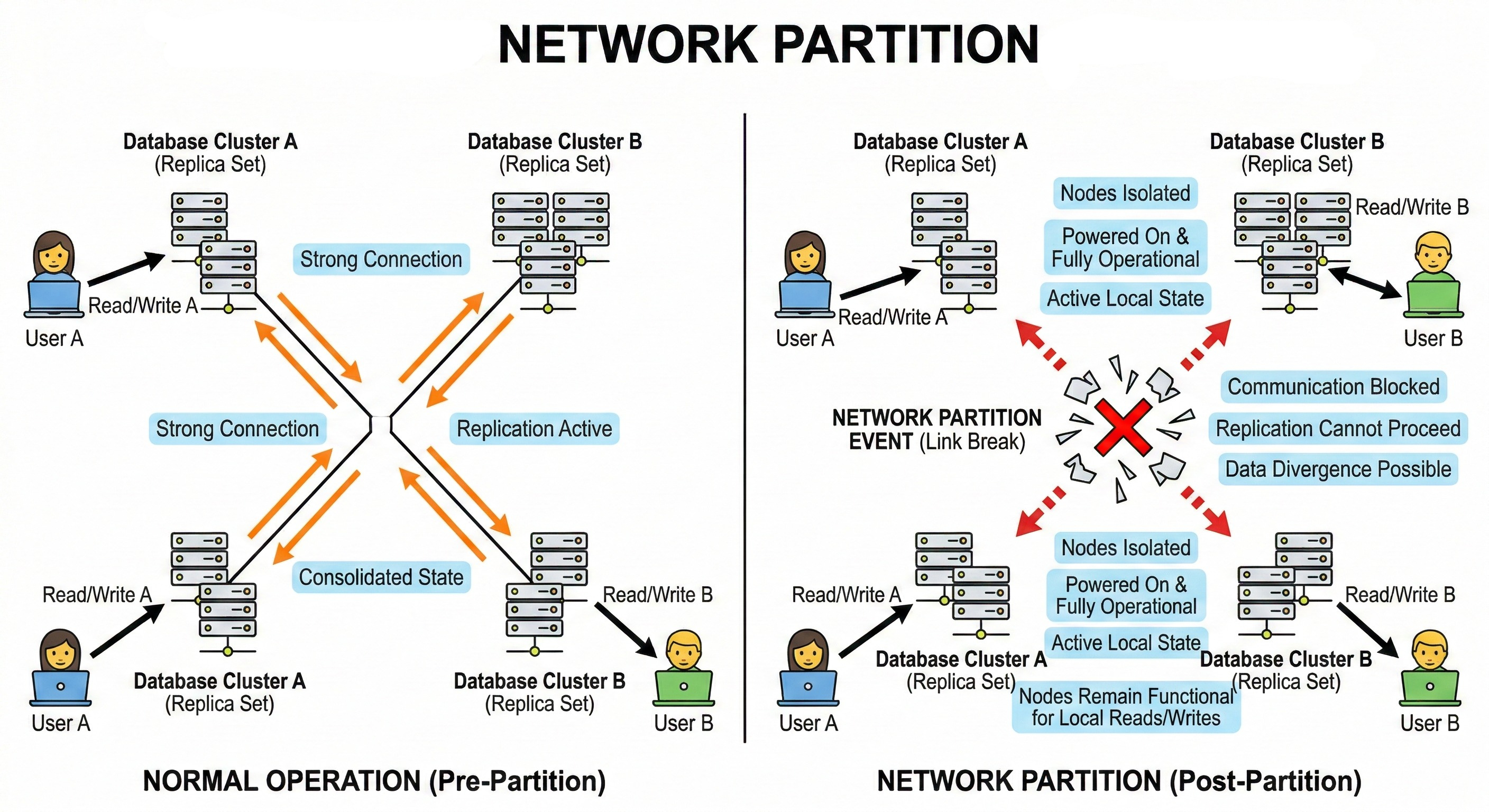
Nodes in a distributed cluster do not share a centralized brain. They operate completely independently and rely solely on network messages to understand the cluster state. Physical networks are notoriously unstable pieces of infrastructure.
When the network link between two or more nodes completely breaks, it is called a network partition.
During a network partition, both isolated nodes remain powered on and fully operational. They simply cannot send or receive replication messages from each other.
Detecting Dropped Connections
Nodes do not have specialized hardware sensors to detect broken cables. They rely entirely on continuous software signals to monitor network health. These continuous signals are technically known as heartbeat messages.
Keep reading with a 7-day free trial
Subscribe to System Design Nuggets to keep reading this post and get 7 days of free access to the full post archives.