
System Design Interview: When to Use an API Gateway vs. Load Balancer
Stop mixing up your architectural layers. We clarify where authentication and SSL decryption should happen in a modern web stack.


Transitioning from a monolithic application to a distributed system introduces a fundamental shift in how data moves.
In a simple setup, a client connects directly to a server. The relationship is one-to-one.
However, as applications scale to support millions of users, this direct connection becomes impossible.
Engineers must introduce intermediate components to manage the flow of information.
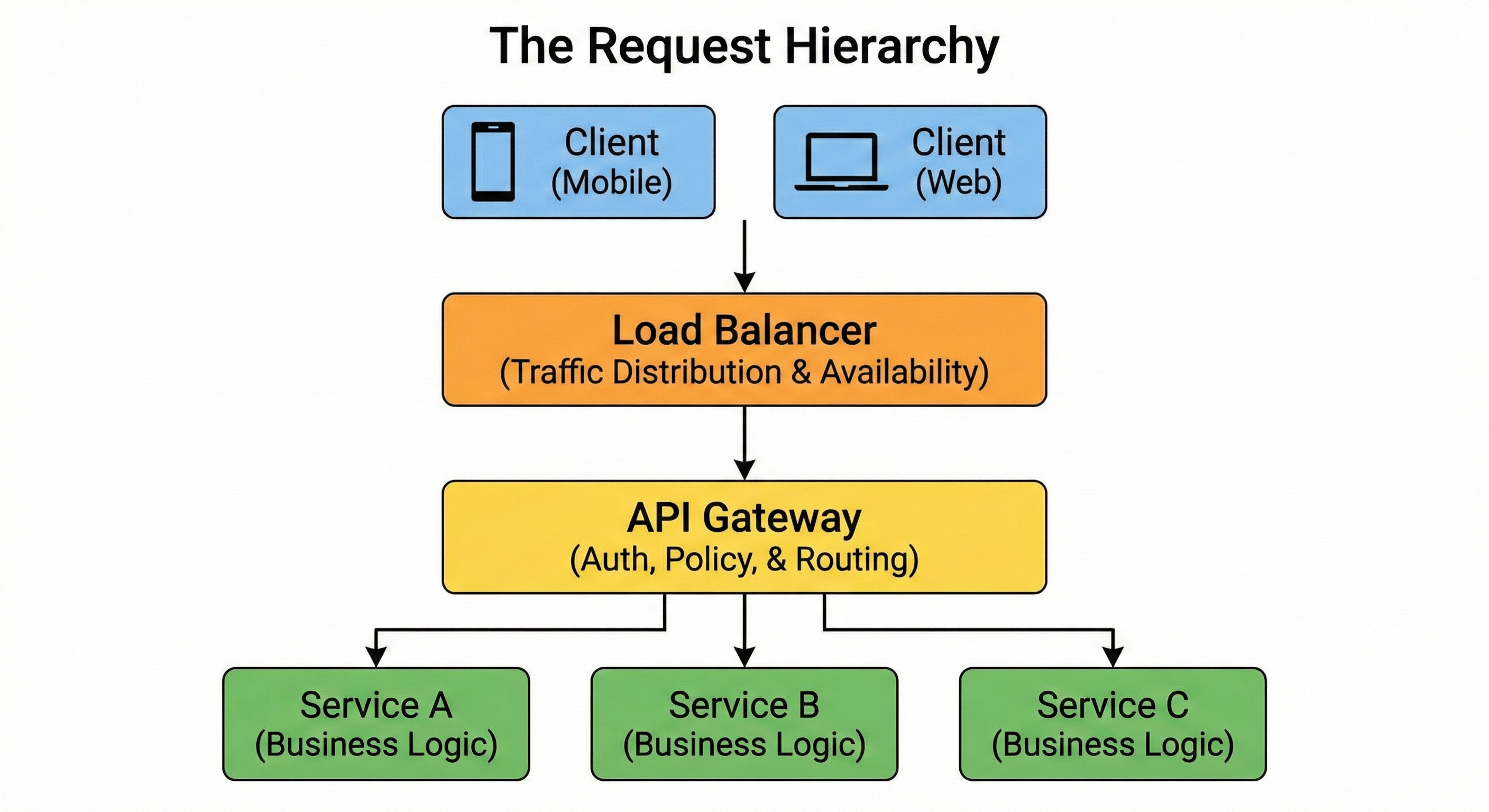
This introduces two critical pieces of infrastructure: the Load Balancer and the API Gateway.
For developers new to system design, these components often appear to perform the same function. Both sit in front of the application code. Both accept requests from the outside world. Both forward those requests to internal servers.
This overlap creates confusion regarding responsibilities. It becomes unclear where to place critical logic such as authentication, data validation, and encryption handling.
A robust system architecture relies on a strict separation of concerns.
This guide breaks down the specific roles of the Load Balancer and the API Gateway. We will explore the technical mechanisms they employ and define exactly where the “logic” of an application should reside.
The Load Balancer: Managing Availability
The primary directive of a Load Balancer is availability. Its function is to ensure that the system remains accessible to users, regardless of the traffic volume or the status of individual servers.
When an application runs on a single server, that server represents a single point of failure.
If the hardware malfunctions or the software crashes, the application goes offline.
To mitigate this, engineers deploy multiple instances of the server. This creates a “server pool.”
The Load Balancer sits between the client and this pool. It acts as a distribution unit. It accepts incoming network connections and allocates them to the servers within the pool.
The Mechanism of Traffic Distribution
The Load Balancer makes decisions based on efficiency and capacity. It does not typically inspect the business intent of the request.
Instead, it utilizes algorithms to optimize resource usage.
Round Robin is the most fundamental algorithm. The Load Balancer maintains a list of available servers. It forwards the first request to the first server, the second request to the second server, and so on.
Once it reaches the end of the list, it loops back to the beginning. This ensures a roughly equal distribution of request counts across the pool.
Least Connections is a dynamic algorithm.
In this scenario, the Load Balancer monitors the number of active connections each server is currently maintaining.
When a new request arrives, the Load Balancer identifies the server with the lowest count of active connections and routes the traffic there. This is particularly effective when request processing times vary significantly.
IP Hash provides consistency.
The Load Balancer performs a mathematical calculation on the client’s IP address to generate a hash key. This key is mapped to a specific server.
As long as the client’s IP address remains constant, they will always be routed to the same server. This is useful for applications that store temporary session data on the specific server instance.
