
ACID vs. BASE: The System Design Interview Guide to Database Consistency
Master the core trade-off in system design: ACID vs. BASE. Learn when to prioritize Data Consistency (Banking) over High Availability (Social Media), and understand Eventual Consistency,.

Designing a robust system isn’t just about writing clean code; it is about making hard decisions on how your data behaves when things go wrong.
Every large software system has to balance two opposing things: speed and reliability.
When you are architecting a database, you are forced to choose a philosophy.
Do you want your system to be a strict perfectionist that guarantees absolute accuracy every single time, even if it means slowing down?
Or do you want a system that is flexible and incredibly fast, even if it means the data isn’t perfectly synchronized for a few seconds?
You generally cannot have both at the maximum level simultaneously. You have to prioritize one over the other.
This specific trade-off is the core difference between ACID and BASE.
It is about understanding the “personality” of your database.
Let’s break it down.
What is a Database Transaction?
Before we can pick a side, we need to define the basic unit of work in a database. We call this a Database Transaction.
A transaction is not just about money.
In computer science, a transaction is a single logical operation that might involve multiple steps.
Think of it like purchasing an item online. The “transaction” involves several steps happening behind the scenes:
The system checks if the item is in stock.
It subtracts the item from the inventory.
It charges your credit card.
It generates an order confirmation.
If any one of these steps fails, the whole thing should fail. You don’t want to be charged if the item is out of stock.
You want these steps to be treated as one single, indivisible unit.
How the database handles this unit of work depends on the model you choose: ACID or BASE.
Part 1: ACID (The Strict Perfectionist)
For decades, the gold standard for databases (especially Relational Databases like MySQL or PostgreSQL) has been the ACID model.
ACID systems are designed to prioritize consistency and safety above all else. They are the strict perfectionists of the data world.
If the database cannot guarantee the data is 100% correct right now, it will refuse to do the work.
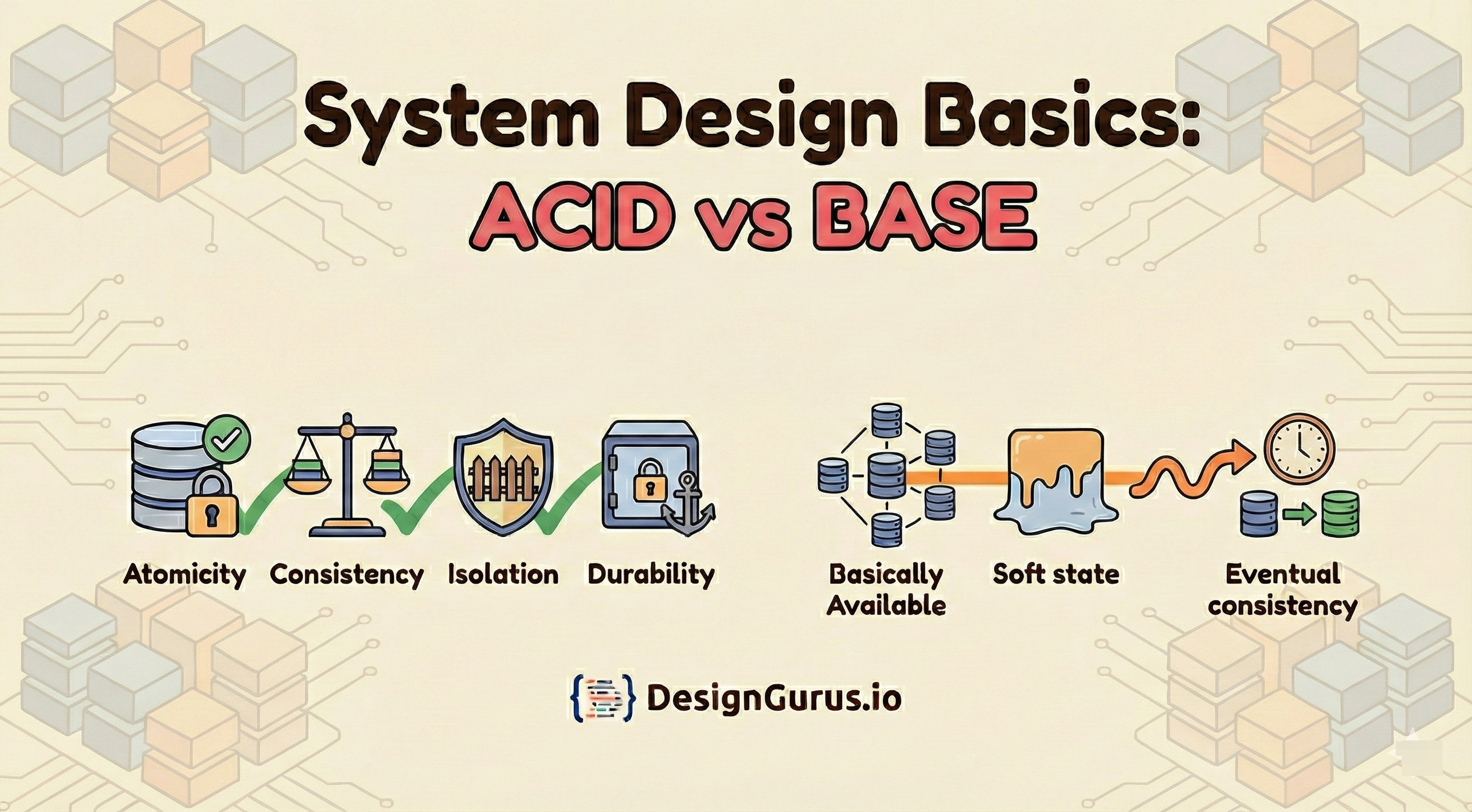
ACID stands for Atomicity, Consistency, Isolation, and Durability.
Let’s look at what actually happens behind the scenes for each.
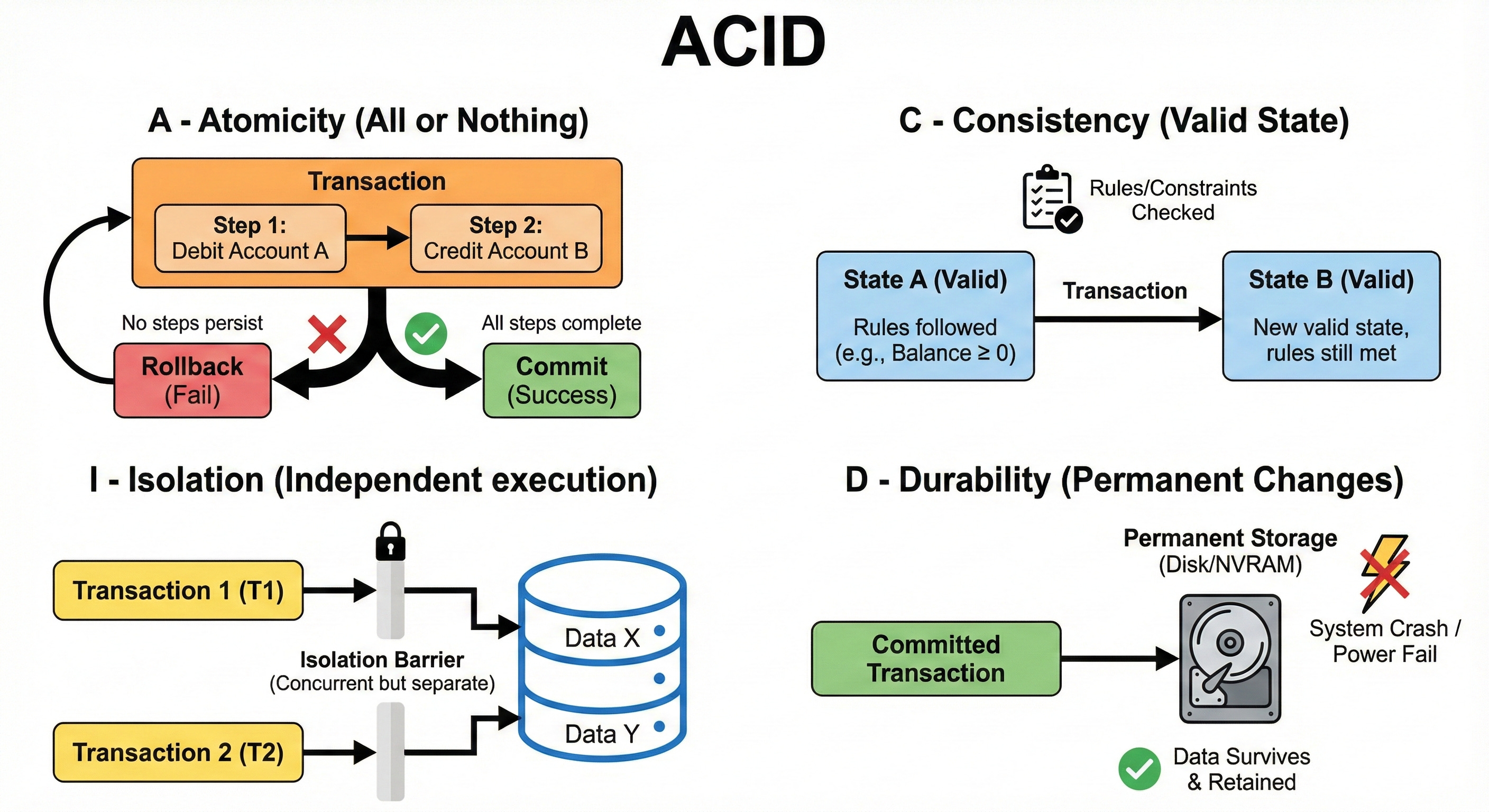
Atomicity: All or Nothing
Atomicity guarantees that a transaction is treated as a single unit. It either happens completely, or it doesn’t happen at all.
There is no halfway state.
Behind the Scenes: When a database starts a transaction, it keeps a log. If you try to update ten different rows in a table and the power goes out after the fifth row, the database detects this “half-finished” state when it restarts.
Because of Atomicity, the database will look at its log, see that the transaction never finished, and rollback (undo) those five changes. It cleans up the mess so it looks like the transaction never happened.
Consistency: Follow the Rules
Consistency ensures that a transaction brings the database from one valid state to another valid state.
The database must follow all the rules defined in its schema (like constraints, cascades, and triggers).
Behind the Scenes: Suppose your database has a rule that says a “User ID” column cannot be empty. If you try to run a transaction that creates a user without an ID, the database will stop you immediately.
It checks the data before writing it permanently. If the data violates your rules, the transaction is aborted. This prevents data corruption.
Isolation: Waiting for Your Turn
In a real application, you don’t just have one user.
You have thousands.
Many of them might try to access the same data at the exact same time.
Isolation ensures that concurrent transactions (transactions happening at the same time) do not interfere with each other.
Behind the Scenes: Imagine two people try to buy the last concert ticket at the exact same millisecond. Without isolation, the system might sell the ticket to both of them.
To prevent this, ACID databases use locking.
When User A starts buying the ticket, the database puts a “lock” on that specific row of data.
When User B tries to buy it, the database makes User B wait until User A is finished.
Once User A finishes, the lock is released, and User B sees that the ticket is sold out.
Durability: Written in Stone
Durability guarantees that once a transaction has been committed (confirmed successful), it will remain so, even in the event of a power loss, crash, or error.
Behind the Scenes: When the database tells you “Success,” it means the data has been physically written to a non-volatile storage, like a hard drive or SSD.
It usually writes to a “Write-Ahead Log” first.
Even if the entire server crashes one millisecond after you got the success message, your data is safe.
When the server turns back on, it reads the saved log and reconstructs your data.
The Problem with ACID
You might be thinking that ACID sounds perfect.
Why would anyone ever want a database that isn’t safe, consistent, and durable?
The problem is scaling.
ACID works beautifully when everything runs on a single server.
But the moment you become a massive company like Facebook, Google, or Netflix, a single server is not enough. You need to spread your data across hundreds of servers all over the world.
When you spread data out, keeping everything perfectly synchronized in real-time is incredibly difficult.
If a user in Tokyo updates their profile, forcing a server in New York to instantly lock and update before anyone else can load the page would make the system painfully slow.
ACID is safe, but it is hard to scale horizontally.
This is where BASE comes in.
Part 2: BASE
BASE was created for the era of Big Data and distributed systems. It is the philosophy often used by NoSQL databases (like Cassandra, DynamoDB, or MongoDB).
BASE prioritizes availability and speed over instant perfection. It accepts that the data might be a little bit “stale” or inaccurate for a few seconds, as long as the system remains fast and online.
BASE stands for Basically Available, Soft state, and Eventual consistency.
Basically Available
This means the system guarantees availability. If a user tries to read data, they will get a response.
Behind the Scenes: In an ACID system, if a part of the database is broken or busy, the system might say, “Error, please try again.”
In a BASE system, the goal is to always give an answer.
If the main server with the most up-to-date data is down, the system might route the user to a backup server.
That backup server might have slightly old data, but the system decides it is better to show something rather than show an error page.

Soft State
“Soft State” is a fancy way of saying that the state of the system might change over time, even without new input.
Behind the Scenes: In a strict banking system, the balance only changes when a transaction happens. In a BASE system, the data is constantly “settling.”
Because the data is being copied (replicated) across many different servers, the true “state” of the data is somewhat fluid until all those copies match up. The system doesn’t promise that the data you see right now is the absolute, frozen truth.
Eventual Consistency
This is the most famous and important part of the BASE acronym. It means that if the system stops receiving inputs, eventually all the servers will catch up and have the same data.
Behind the Scenes: Think about posting a photo on Instagram. You hit “post,” and it appears on your phone instantly. However, your friend sitting next to you might not see it on their feed for another 10 seconds.
The system didn’t lock everyone’s phone to update the feed instantly. That would crash the internet. Instead, the update propagated to your local server first, then slowly (in computer time) spread to the servers in your friend’s region.
The system promises that the data will become consistent eventually. It might take a few milliseconds, or it might take a few seconds. But it will happen.
Comparing ACID vs BASE: The Real-World Choice
So, which one do you choose for your System Design Interview?
The answer, as always in engineering, is “it depends.” You have to look at the specific requirements of the app you are building.
When to use ACID (RDBMS / SQL)
You choose ACID when data accuracy is critical and you cannot afford to be wrong, even for a millisecond.
Use cases:
Financial Systems: Banking, stock trading, payment processing. You cannot have “eventual consistency” with a bank balance.
Inventory Management: If you only have one item left in the warehouse, you cannot sell it to two people.
Medical Records: Patient data must be accurate and up to date immediately.
When to use BASE (NoSQL)
You choose BASE when you need to handle massive amounts of data or millions of users, and it is okay if the data is slightly out of sync.
Use cases:
Social Media Feeds: It doesn’t matter if your Like count is 105 or 106 for a few seconds. Speed is more important than precision.
Real-time Analytics: Tracking how many people are on a website. An approximation is fine.
Content Delivery: Serving blog posts or videos to millions of users.
Conclusion
Understanding the trade-off between ACID and BASE is a superpower for a backend developer. It tells interviewers that you understand not just how to code, but how to design systems that survive in the real world.
Here is the summary of what we covered:
ACID is for systems that need strict accuracy (Banking). It focuses on Atomicity, Consistency, Isolation, and Durability.
BASE is for systems that need massive scale and speed (Social Media). It focuses on Basically Available, Soft state, and Eventual consistency.
ACID is pessimistic; it assumes things will break so it locks everything down.
BASE is optimistic; it assumes things will work out eventually so it keeps moving fast.
The Trade-off: You are usually trading immediate consistency for high availability and performance.
Next time you are designing a feature, ask yourself: “If this data is wrong for 2 seconds, will someone lose money?”
If the answer is yes, go with ACID.
If the answer is no, BASE might be your best friend.
Great one.
Superb walkthrough of the consistency tradeoff. The framing around locking mechanisms in ACID really clarifies why horizontal scaling becomes painful at scale. I've seen teams default to ACID out of habit then hit bottlenecks when they needed to distribute. The "will someone lose money" hueristic at the end is exactly the decison framework that separates senior engineers from juniors.