
16 Replication Concepts Every Software Engineer Should Know (Simple Guide for 2026)
Learn sixteen core replication ideas that power large-scale systems. A beginner-friendly guide explaining leaders, multi-leaders, quorums, lag, failover, geo replication, and more with clear examples.

Replication is how large-scale systems stay reliable, fast, and fault-tolerant.
It keeps copies of your data across multiple machines so your application keeps working even when hardware breaks or traffic spikes.
But replication is not a single technique.
It has many patterns and rules that determine how writes happen, how reads behave, and how a cluster recovers when something goes wrong.
This guide explains sixteen essential replication concepts in a clear way, each with practical examples to help you understand how big systems work behind the scenes.
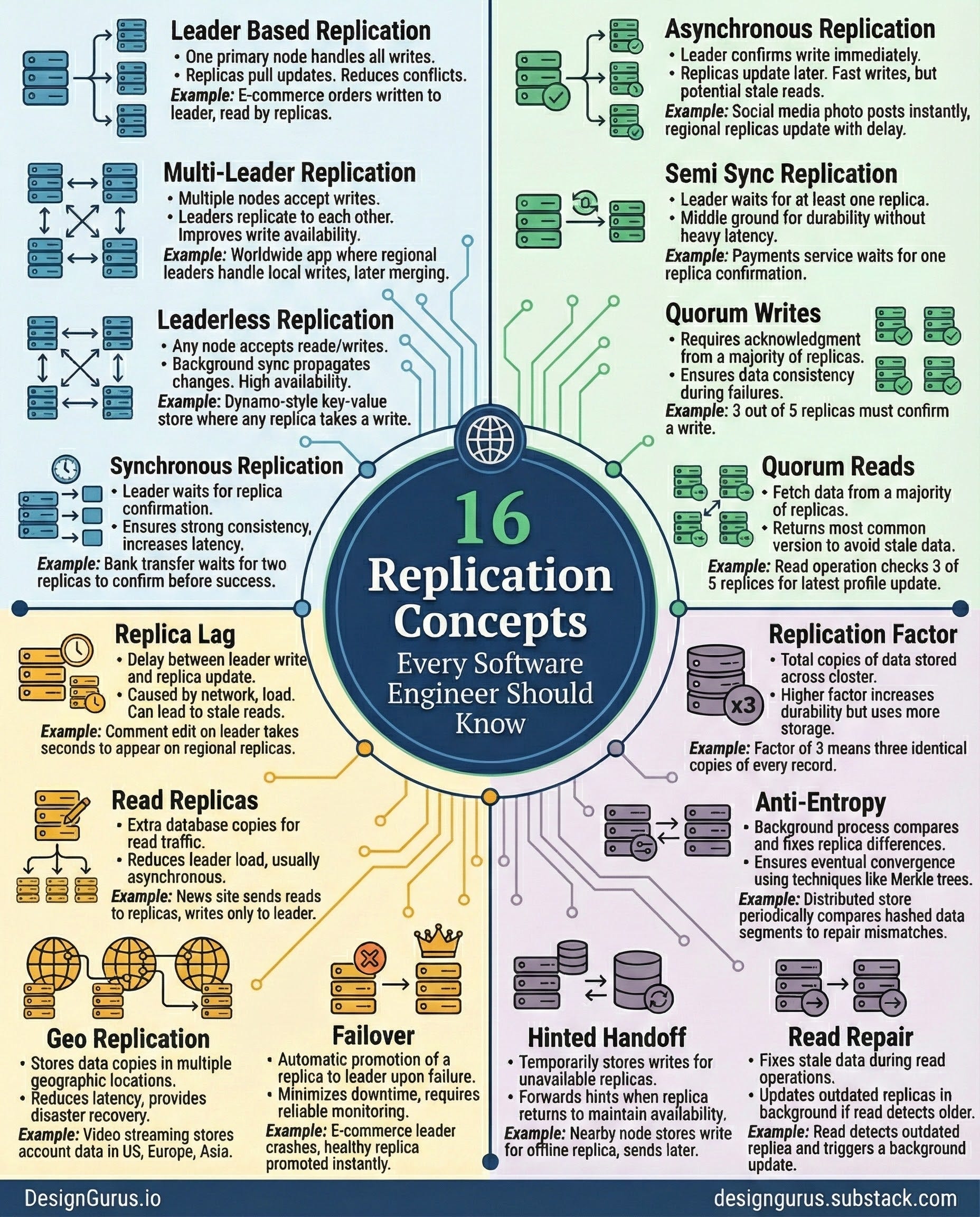
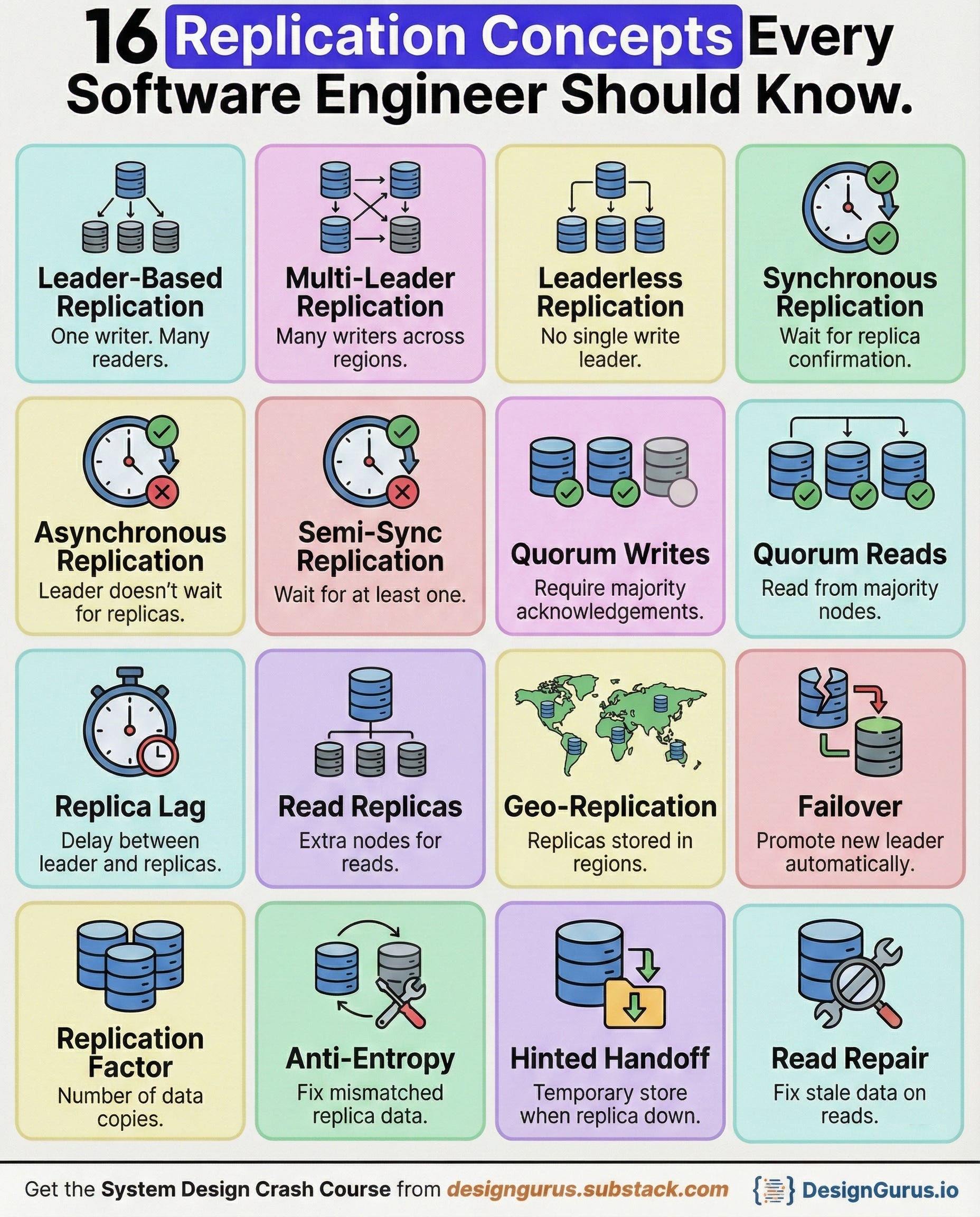
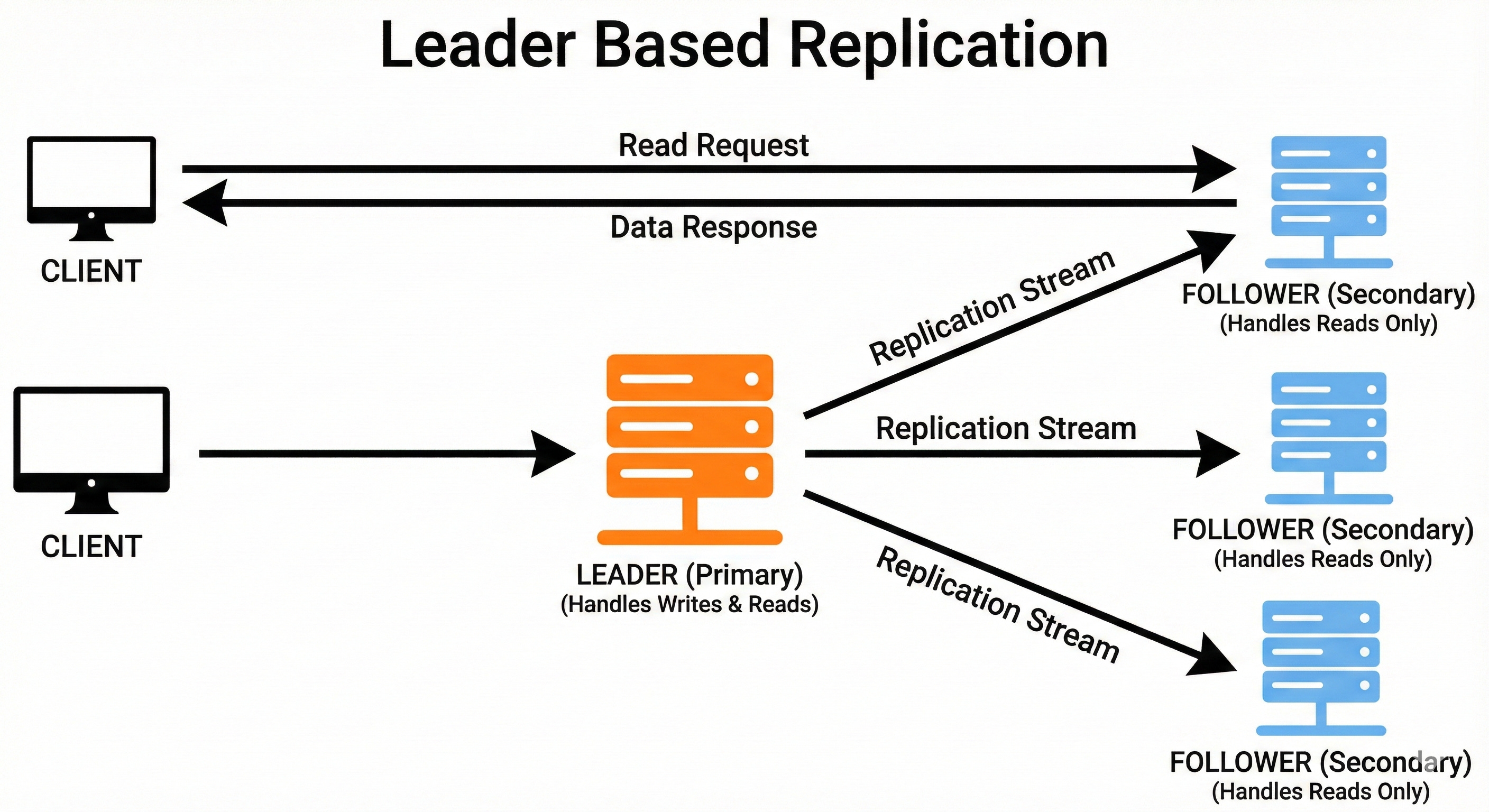
1. Leader Based Replication
Leader based replication has one primary node that handles all writes.
Every write goes to the leader first, ensuring a single, trusted source of truth.
Replicas continuously pull or receive updates from the leader. This setup reduces conflicts because only one node decides how data changes.
Reads can be offloaded to replicas for better performance.
The design is simple and widely used in relational databases and distributed systems.
Example
An e-commerce platform stores each order on the leader node.
When a buyer places an order, it is written to the leader and then replicated to followers.
Customers browsing order history read from replicas, keeping the leader free for important writes.
2. Multi-Leader Replication
Multi-leader replication allows multiple nodes to accept writes at the same time.
Each leader replicates its changes to other leaders. This setup improves write availability across regions and reduces latency for global users.
However, it introduces the possibility of conflicting writes.
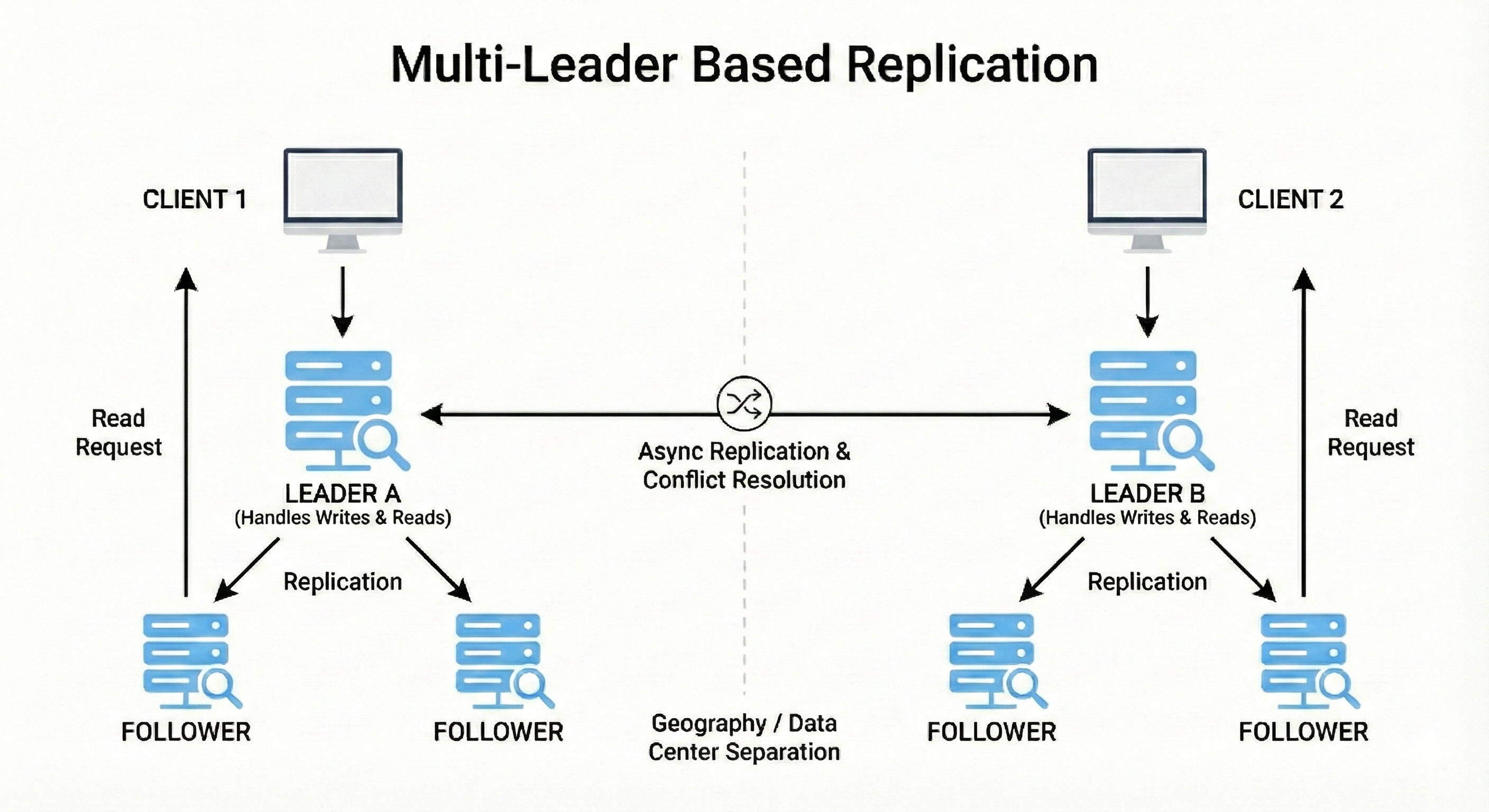
Conflict resolution strategies are required to merge changes correctly. It is commonly used in collaborative apps and multi-region environments.
Example
A worldwide note editing app lets users write updates from different continents.
Each region has its own leader for fast writes.
When two edits collide, the system uses timestamps or merge rules to combine them into a final version.
3. Leaderless Replication
Leaderless replication removes the idea of a primary node. Any node can accept reads or writes.
Writes propagate across replicas using background synchronization processes.
The system must detect and reconcile conflicting versions when nodes disagree. This design offers very high availability because writes never depend on a single machine.
Leaderless systems often use quorum rules to maintain consistency.
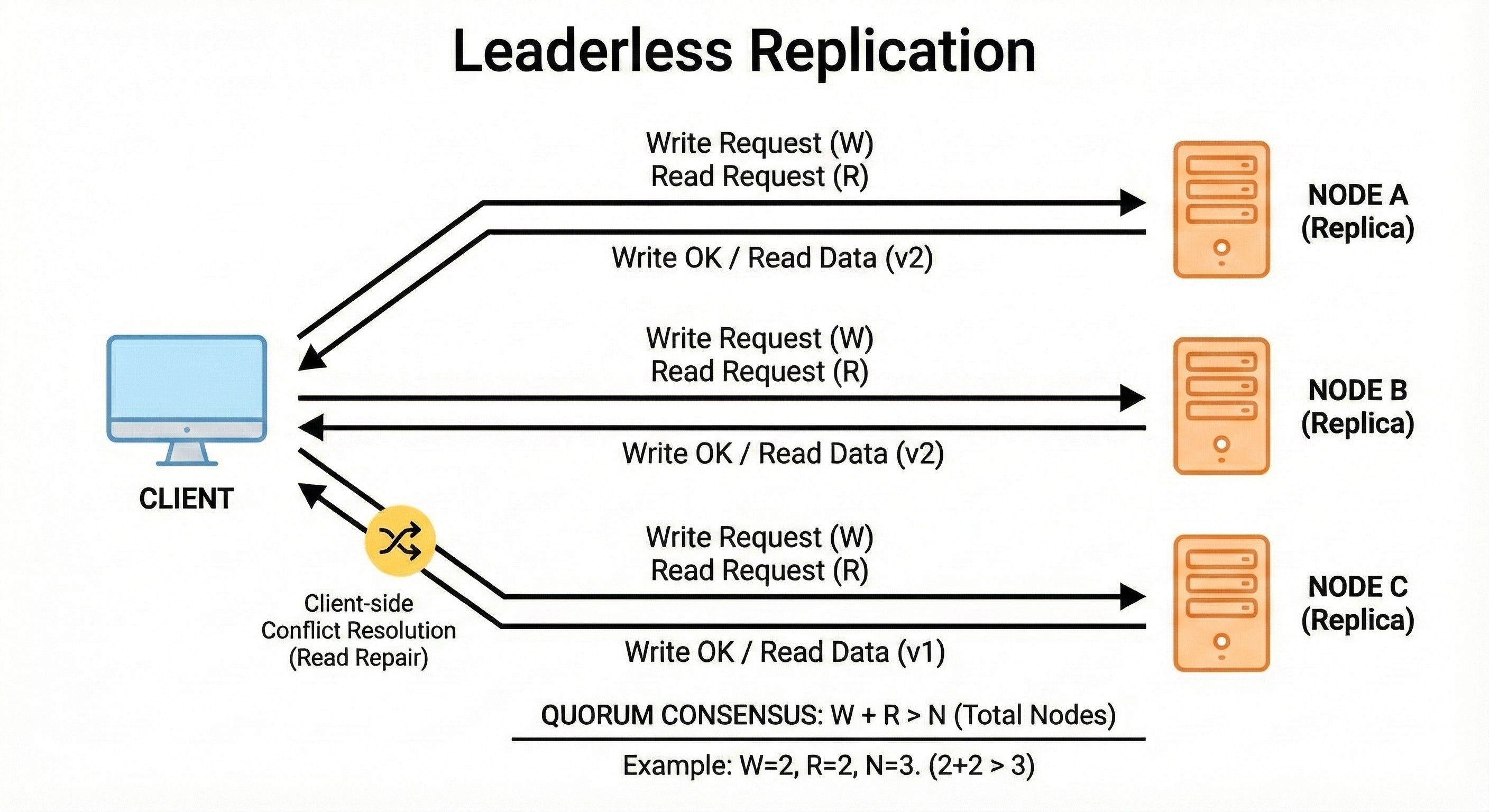
Example
A key-value store like Dynamo lets any replica take a write, even if others are temporarily offline.
When a node comes back online, the cluster exchanges missing versions and resolves differences to reach a consistent state.
4. Synchronous Replication
Synchronous replication requires the leader to wait until all required replicas confirm the write before returning success. This ensures strong consistency because data is guaranteed to be stored on multiple nodes immediately.
The downside is increased latency, especially when replicas are far away.
If one replica is slow or unavailable, the entire write operation slows down.
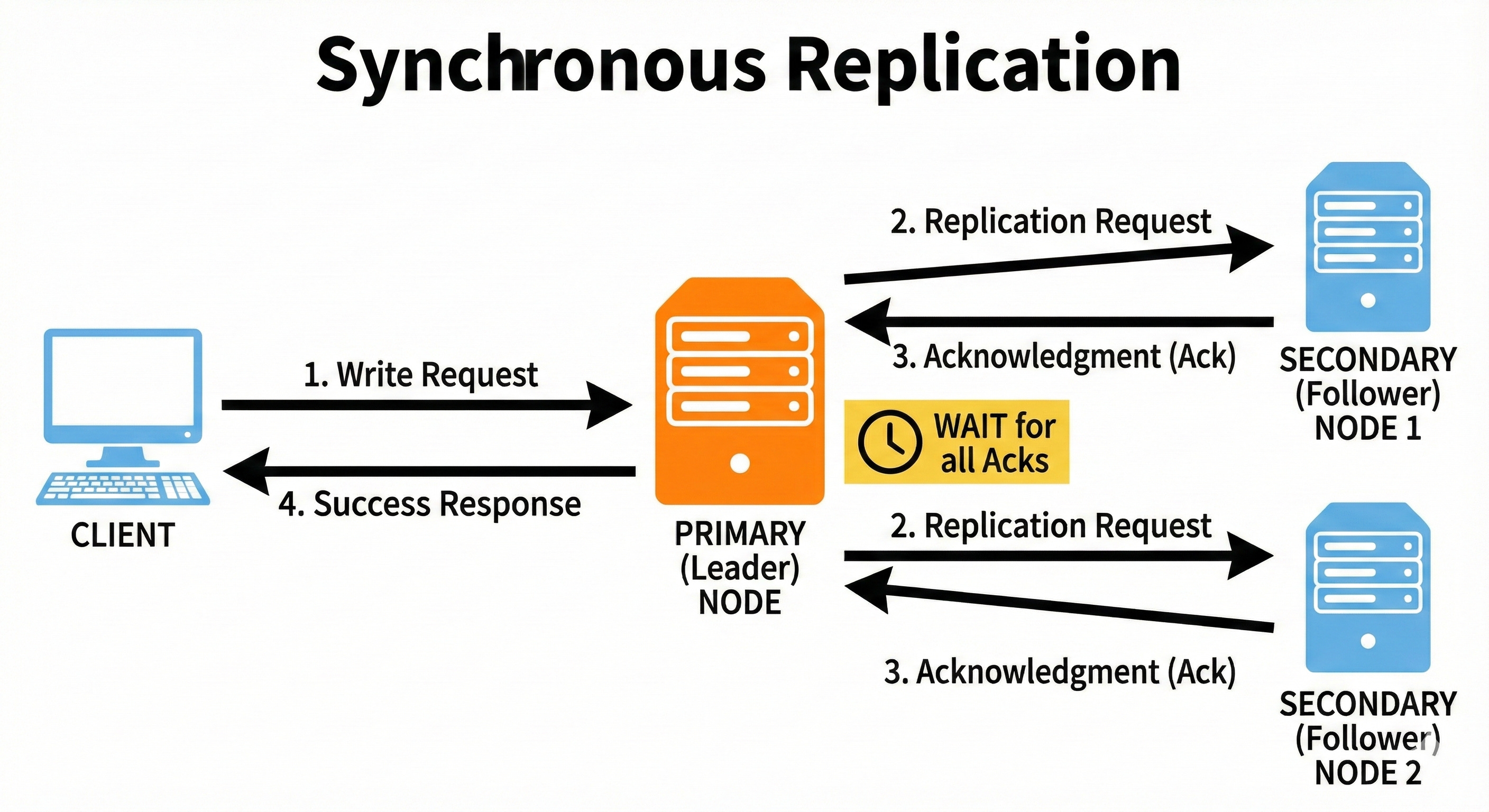
Synchronous replication is ideal for critical data that cannot be lost.
Example
A bank transferring money waits until two other replicas confirm the transaction.
If one replica fails to acknowledge, the write is rejected to avoid inconsistent account balances across the system.
5. Asynchronous Replication
Asynchronous replication allows a leader to confirm a write immediately without waiting for replicas.
Replicas update themselves later.
This makes writes fast, improving performance and availability.
However, replicas might temporarily lag behind, causing stale reads.
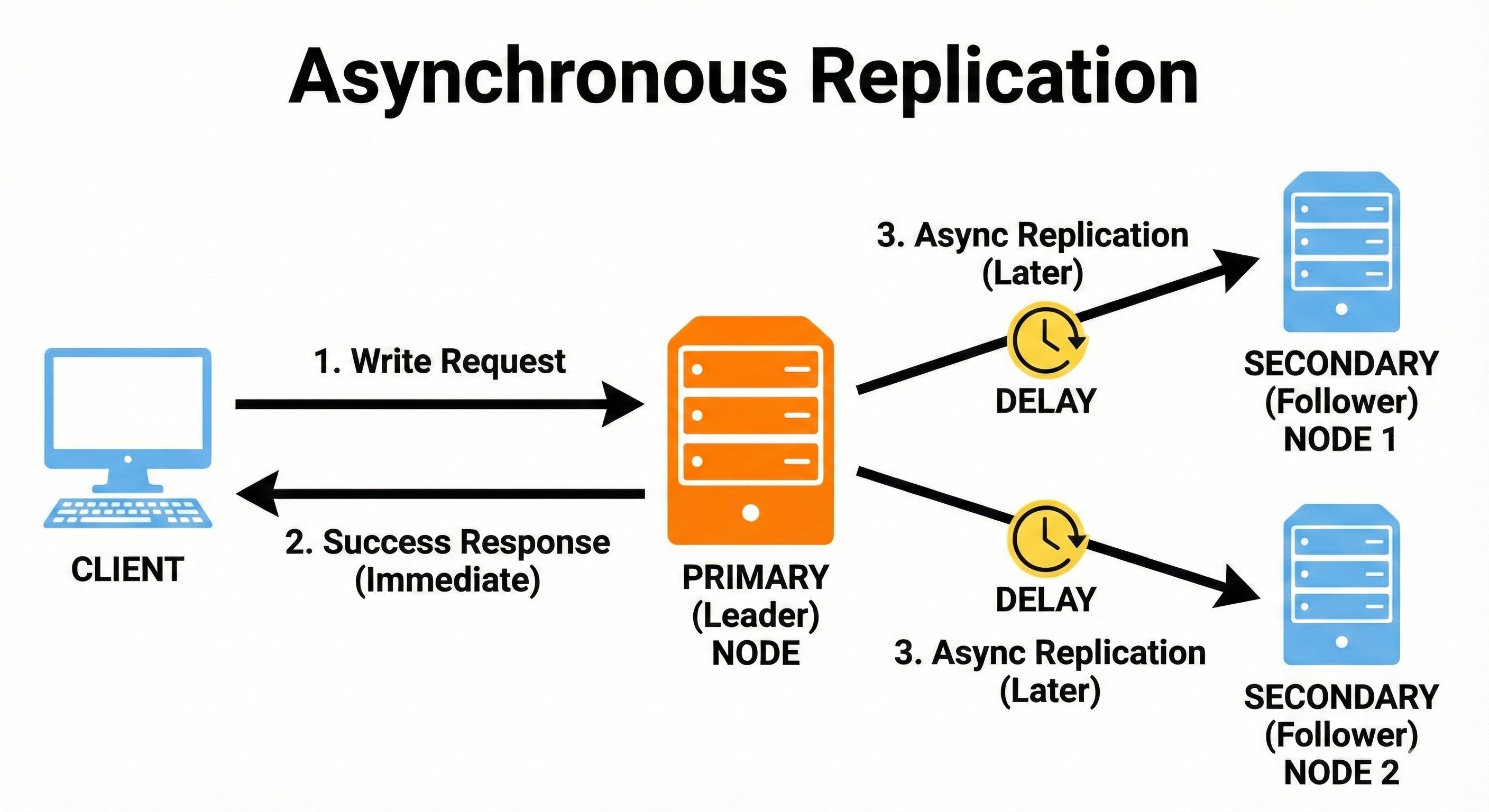
Asynchronous replication is useful for non-critical data where freshness is not always required.
Example
A social media platform posts a user’s new photo instantly.
Users in another region might see the photo a second later because their replica has not yet caught up with the leader’s changes.
6. Semi Sync Replication
Semi-sync replication is a middle ground between synchronous and asynchronous replication.
The leader waits for at least one replica to confirm the write, but not all. This ensures some level of durability without introducing heavy latency.
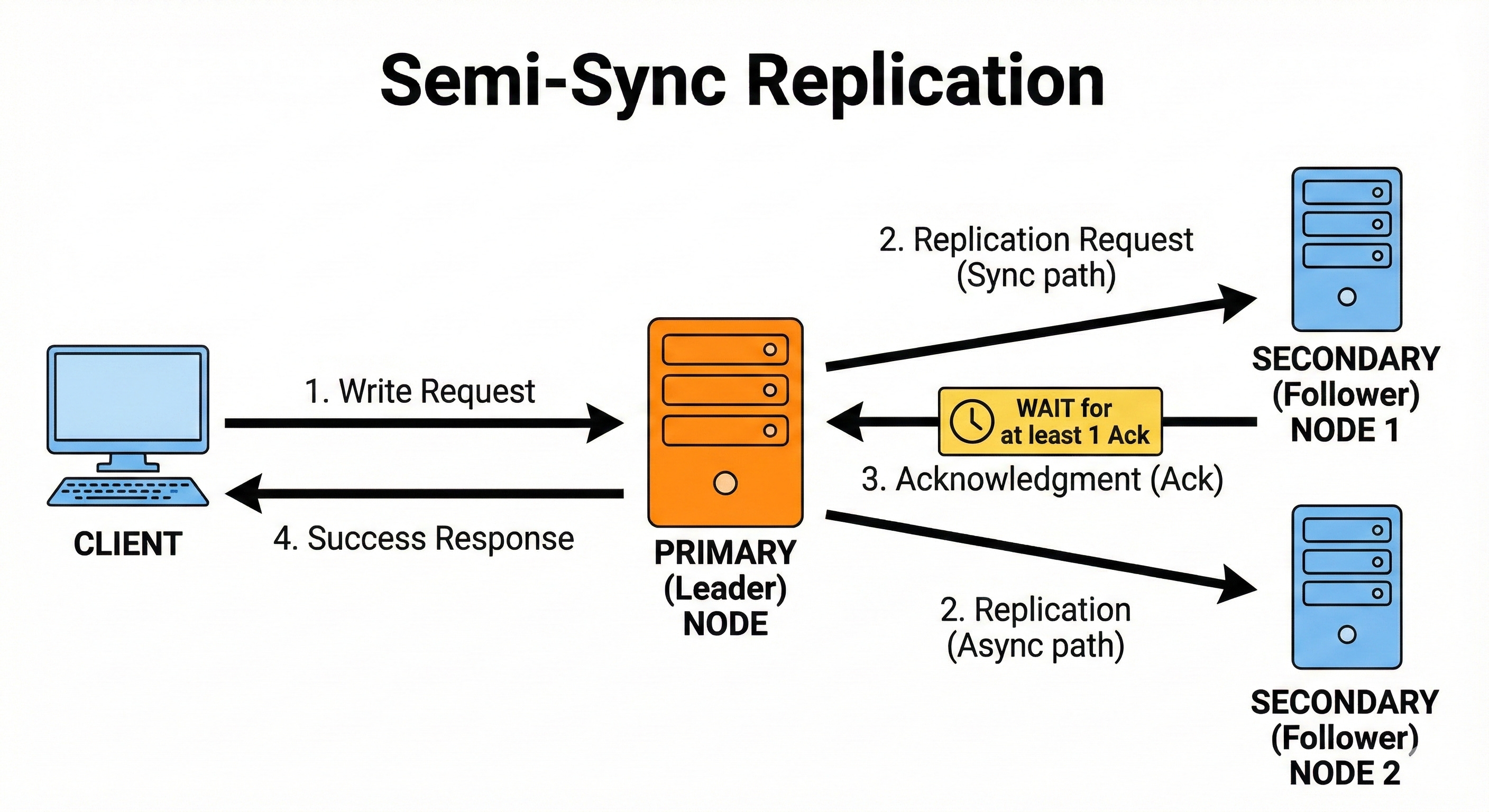
The system can continue even when some replicas are slow. It is often used in high availability configurations.
Example
A payments service waits for one replica to confirm before returning success.
Even if secondary replicas lag, the system still guarantees that at least two copies of the transaction exist.
7. Quorum Writes
A quorum write requires acknowledgment from a majority of replicas before marking a write as successful.
Majority means more than half of the nodes. This ensures data remains consistent even if some replicas fail.
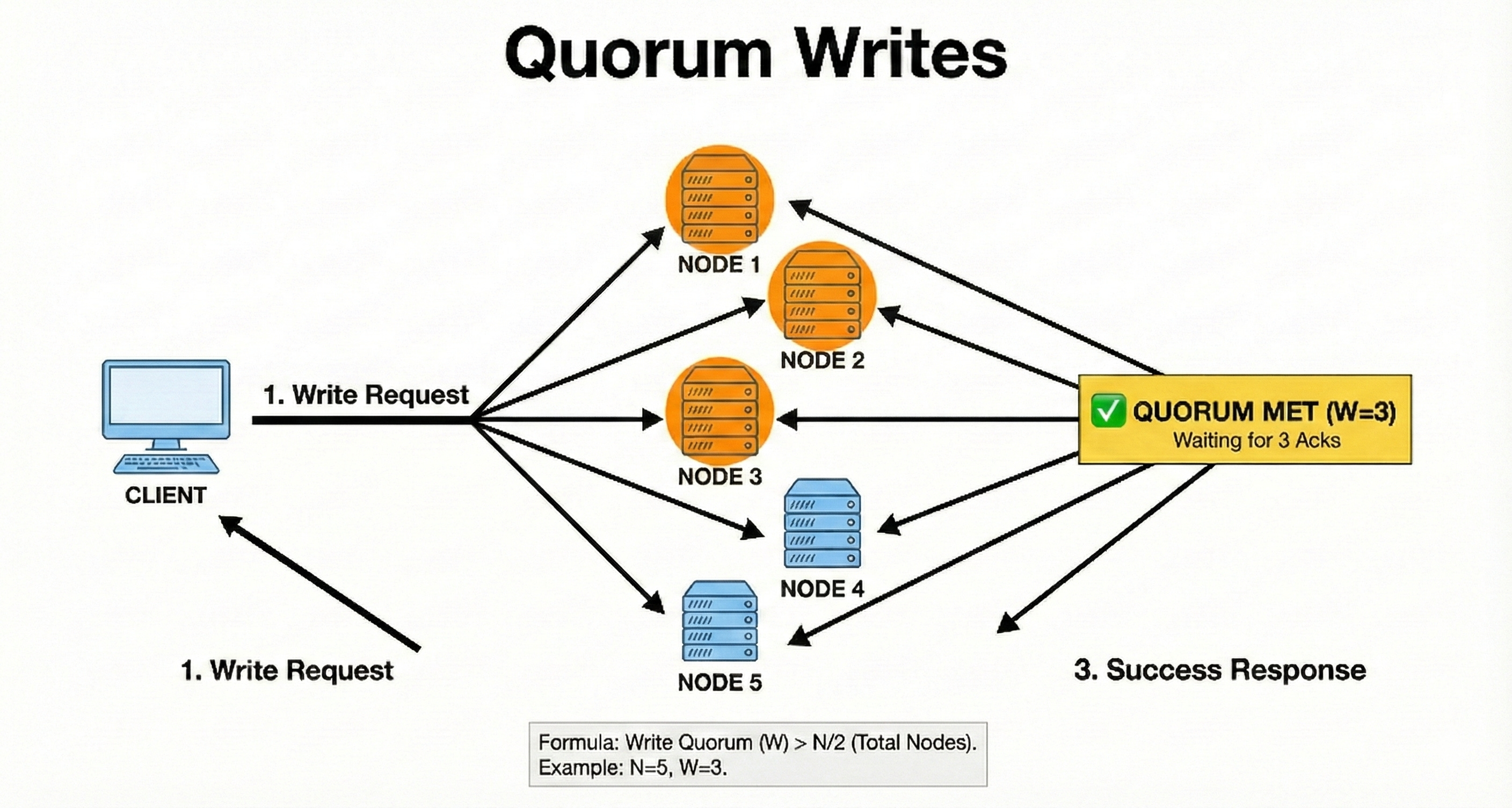
Quorum writes reduce the chance of losing data during partial failures.
They are a reliable strategy for leaderless and distributed systems.
Example
If you have five replicas, at least three must confirm the write. Even if two nodes go offline, the system still knows which version is correct because the majority stored it.
8. Quorum Reads
Quorum reads fetch data from a majority of replicas to ensure the returned value is up to date.
If replicas disagree, the system chooses the version that most nodes have.
This helps avoid stale reads in eventually consistent systems.
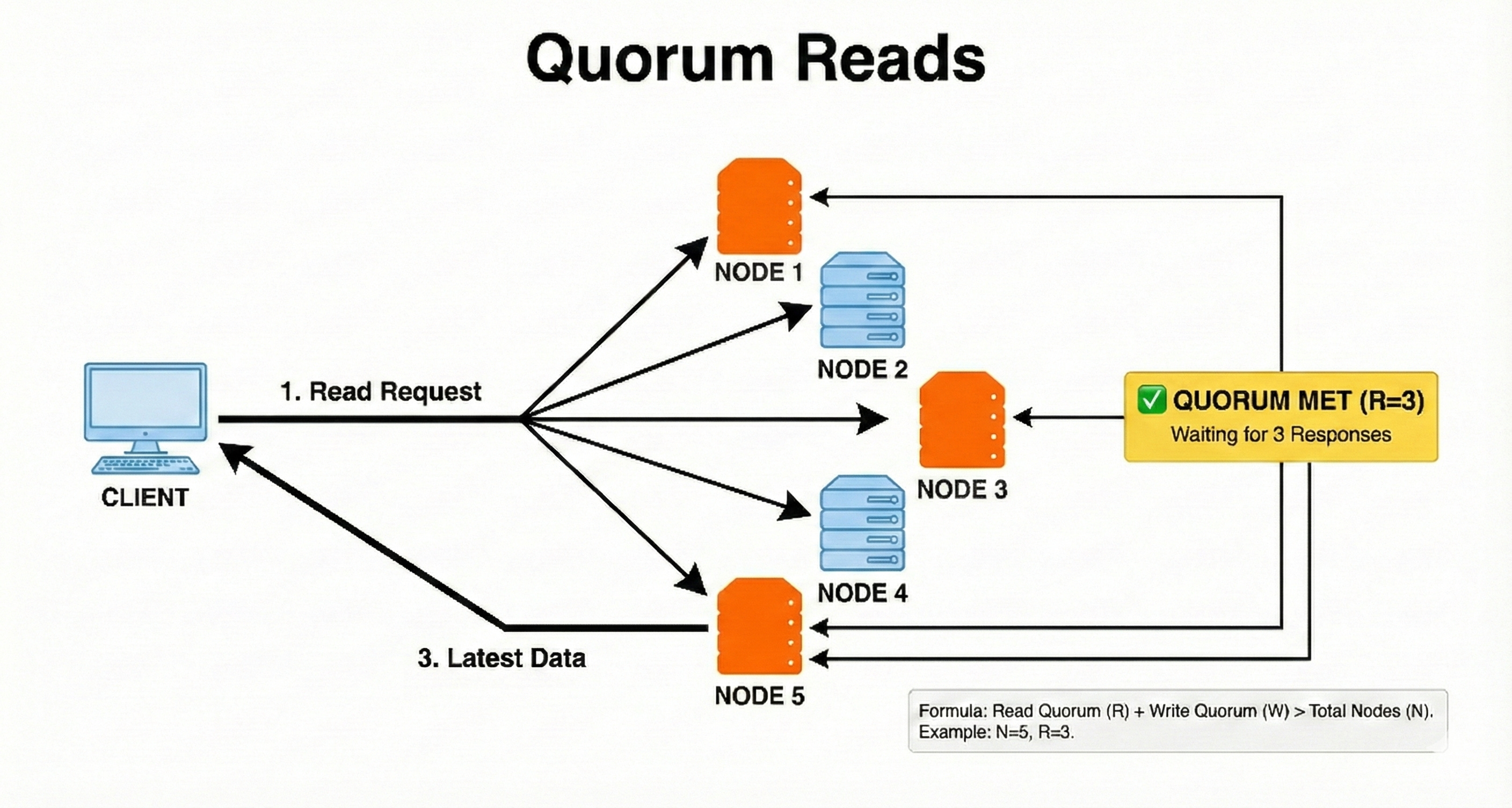
Quorum reads often work together with quorum writes to ensure strong outcomes.
Example
After a user updates their profile, a read operation checks three out of five replicas. Even if one replica is outdated, the system returns the version that the majority agrees on.
9. Replica Lag
Replica lag refers to the delay between when the leader writes data and when replicas apply the update.
Lag can happen due to slow networks, overloaded replicas, or heavy traffic.
Large lag can create stale responses and inconsistent behavior.
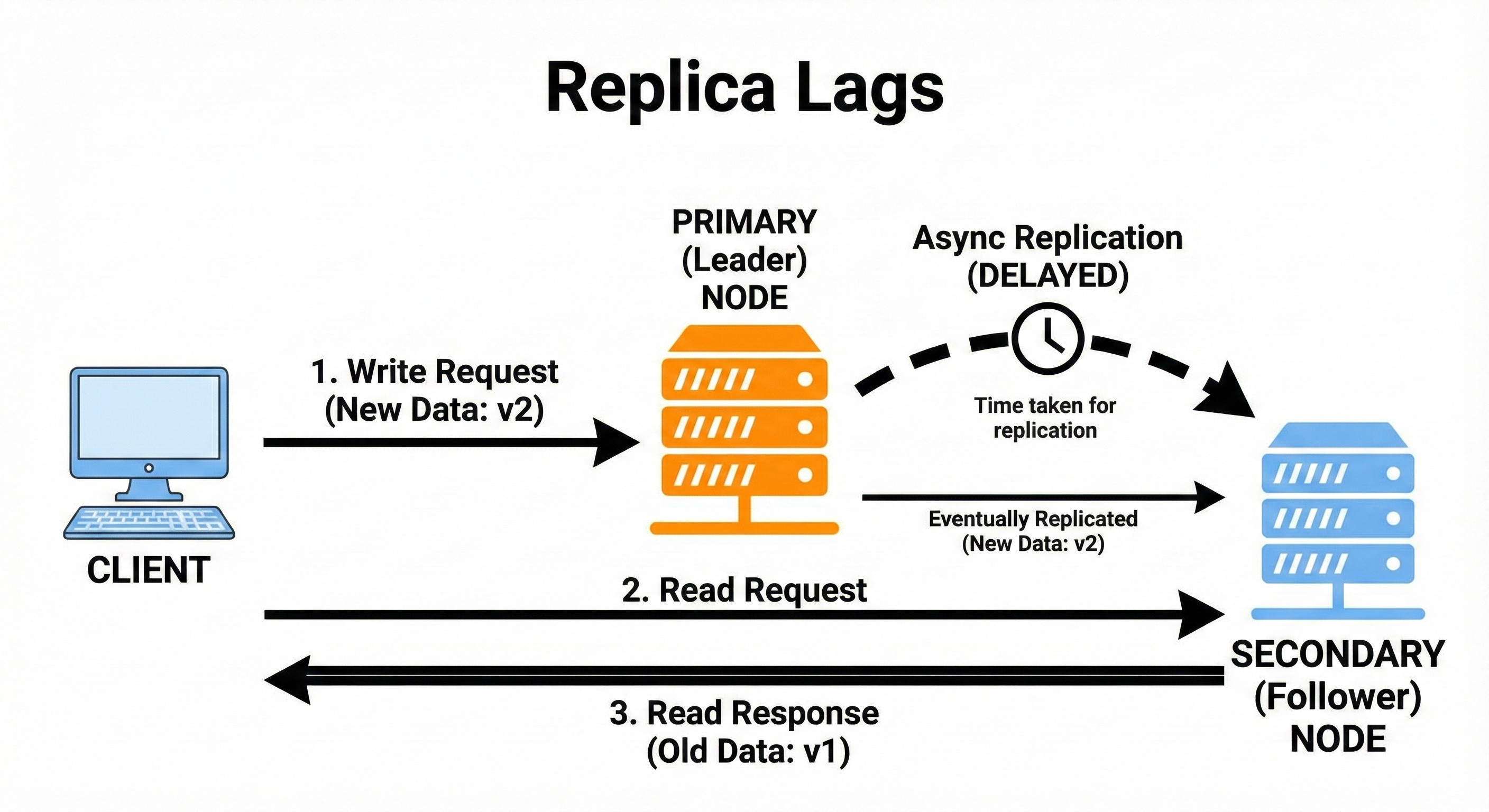
Monitoring lag is essential for healthy distributed systems.
Replicas with high lag are sometimes removed from critical read paths.
Example
A user edits a comment. The leader updates instantly, but a replica in another region applies the change after three seconds. Readers in that region momentarily see the old comment.
10. Read Replicas
Read replicas are extra copies of your database created specifically to serve read traffic.
They reduce load on the leader, improving performance and availability.
Read replicas are usually asynchronously updated, so they might not always have the latest data.
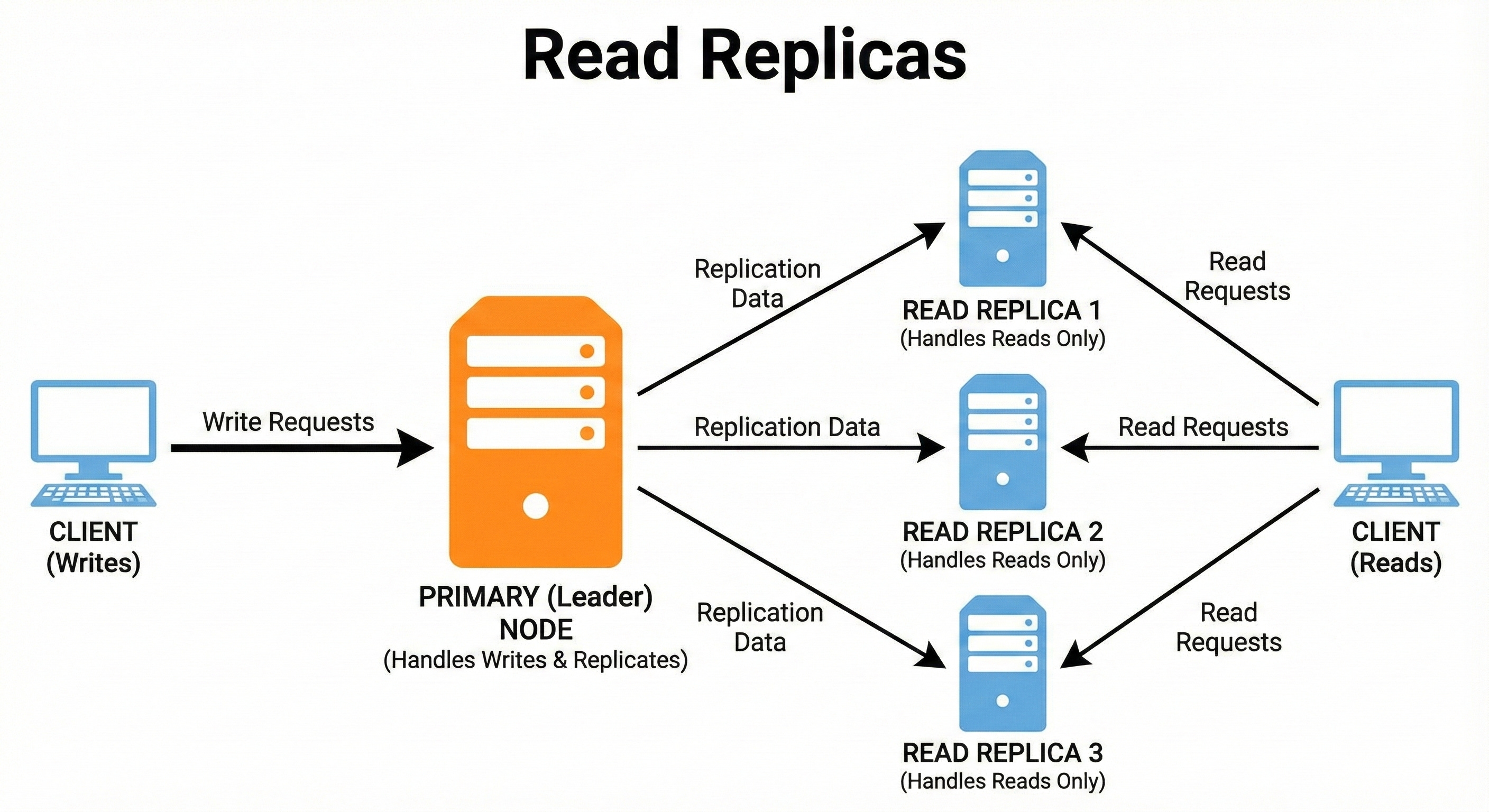
They are extremely useful for read-heavy applications.
Example
A news website sends article reading requests to multiple read replicas. The leader only handles publishing new articles and updates, keeping write performance stable during peak load.
11. Geo Replication
Geo replication stores copies of data in multiple geographic locations.
This reduces latency for global users because they read from the closest region.
It also provides strong disaster recovery since data exists across continents.
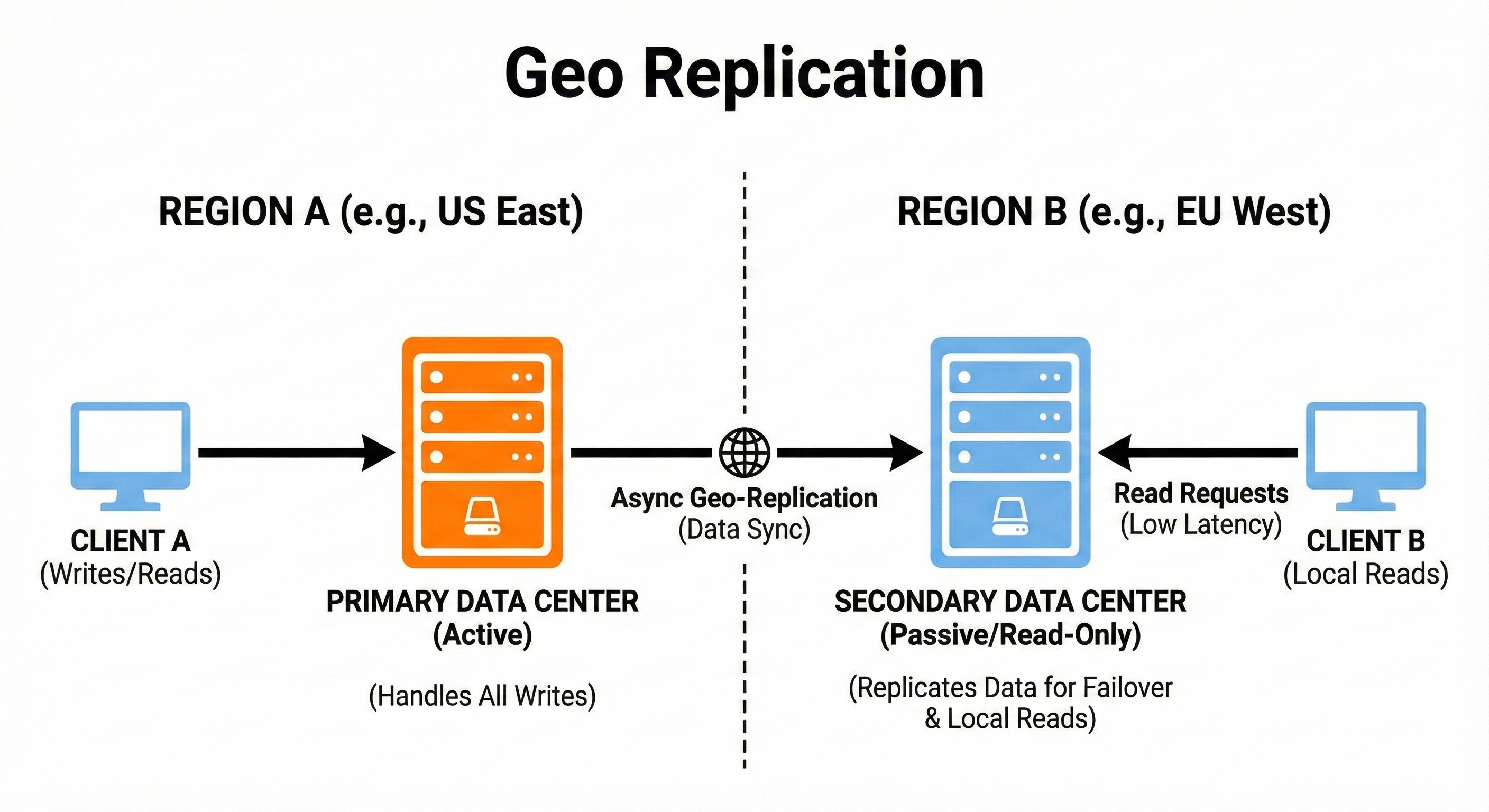
Geo replication can be synchronous or asynchronous, depending on consistency needs.
Example
A video streaming platform stores account data in the US, Europe, and Asia.
Users log in faster because their requests stay within their region instead of traveling across the world.
12. Failover
Failover is the process of automatically promoting a replica to leader when the current leader fails.
This keeps the system running with minimal downtime.
Failover requires reliable monitoring to detect failures quickly.
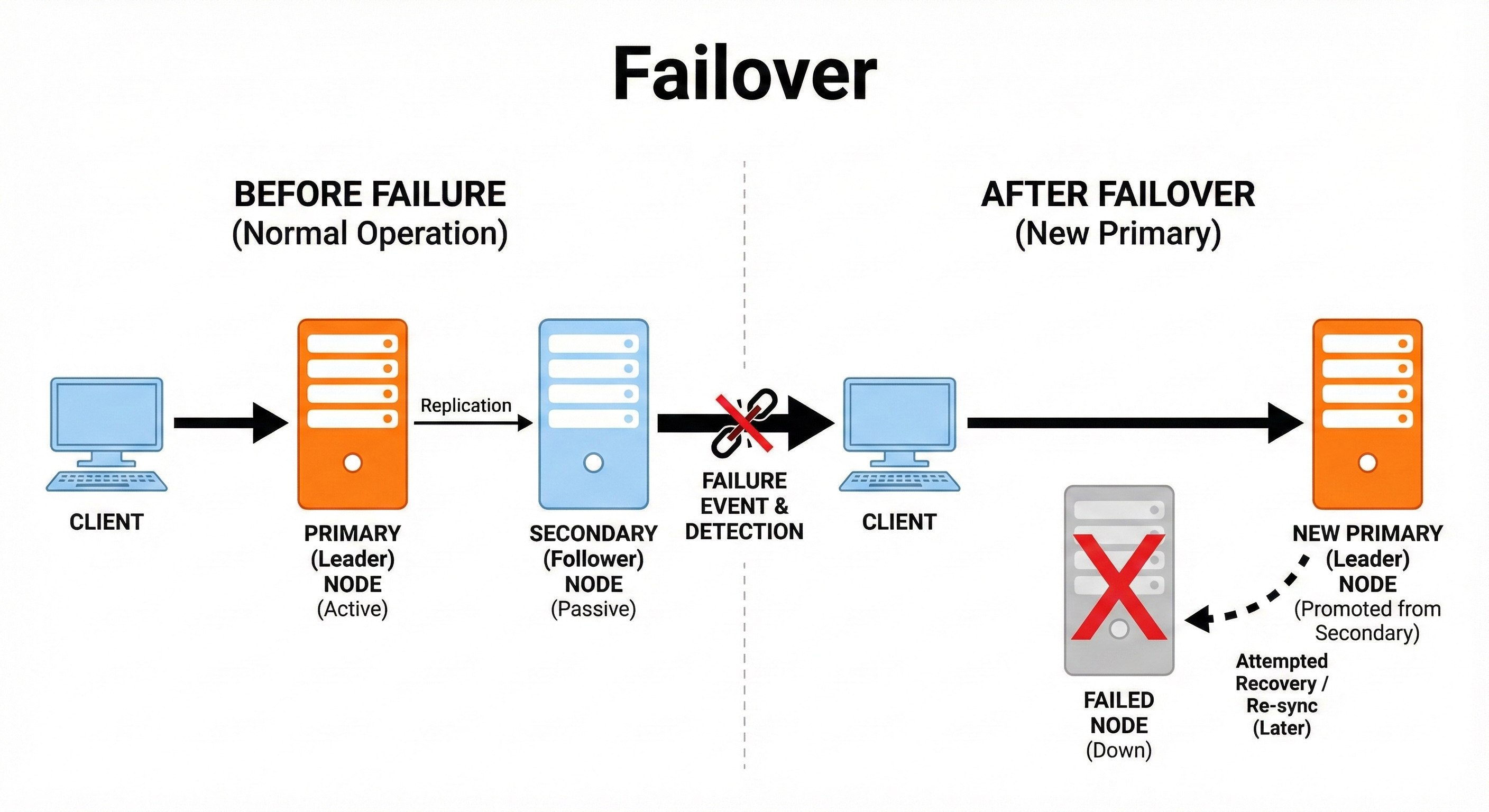
There must also be a safe method to promote replicas without creating conflicting leaders.
Example
If the leader database in an e-commerce service crashes, a healthy replica is promoted within seconds.
New orders can still be placed, and users do not experience outages.
13. Replication Factor
Replication factor is the total number of copies of data stored across the cluster.
A higher replication factor increases durability and fault tolerance.
However, it also uses more storage and network bandwidth. Choosing the right replication factor depends on how critical the data is.
Many systems use a factor of three as a balance between safety and cost.
Example
If the replication factor is three, the system stores three identical copies of every record.
Even if two nodes unexpectedly fail, the data is still safe because one copy survives.
14. Anti-Entropy
Anti-entropy is the background process that compares replicas and fixes differences. It ensures all nodes eventually converge to the same data.
Anti-entropy often uses efficient data structures like Merkle trees to detect mismatches quickly.
It does not happen on every write but runs periodically. This is essential in leaderless and eventually consistent databases.
Example
A distributed store compares hashed segments of data between nodes.
If the hashes differ, the system finds the mismatched keys and copies the correct values to repair the replica.
15. Hinted Handoff
Hinted handoff temporarily stores writes intended for a replica that is currently unavailable.
When the replica comes back online, the stored hints are forwarded to it. This helps the system remain available during small failures.
It prevents data loss and reduces the need for heavy repairs later.
Example
If a replica goes offline during a write request, a nearby node stores the write as a hint.
Once the replica returns, the node forwards the missed updates so the replica becomes consistent again.
16. Read Repair
Read repair fixes stale data during read operations.
If a read detects that one or more replicas have outdated values, the system updates those replicas in the background. This improves consistency without requiring heavy background sync.
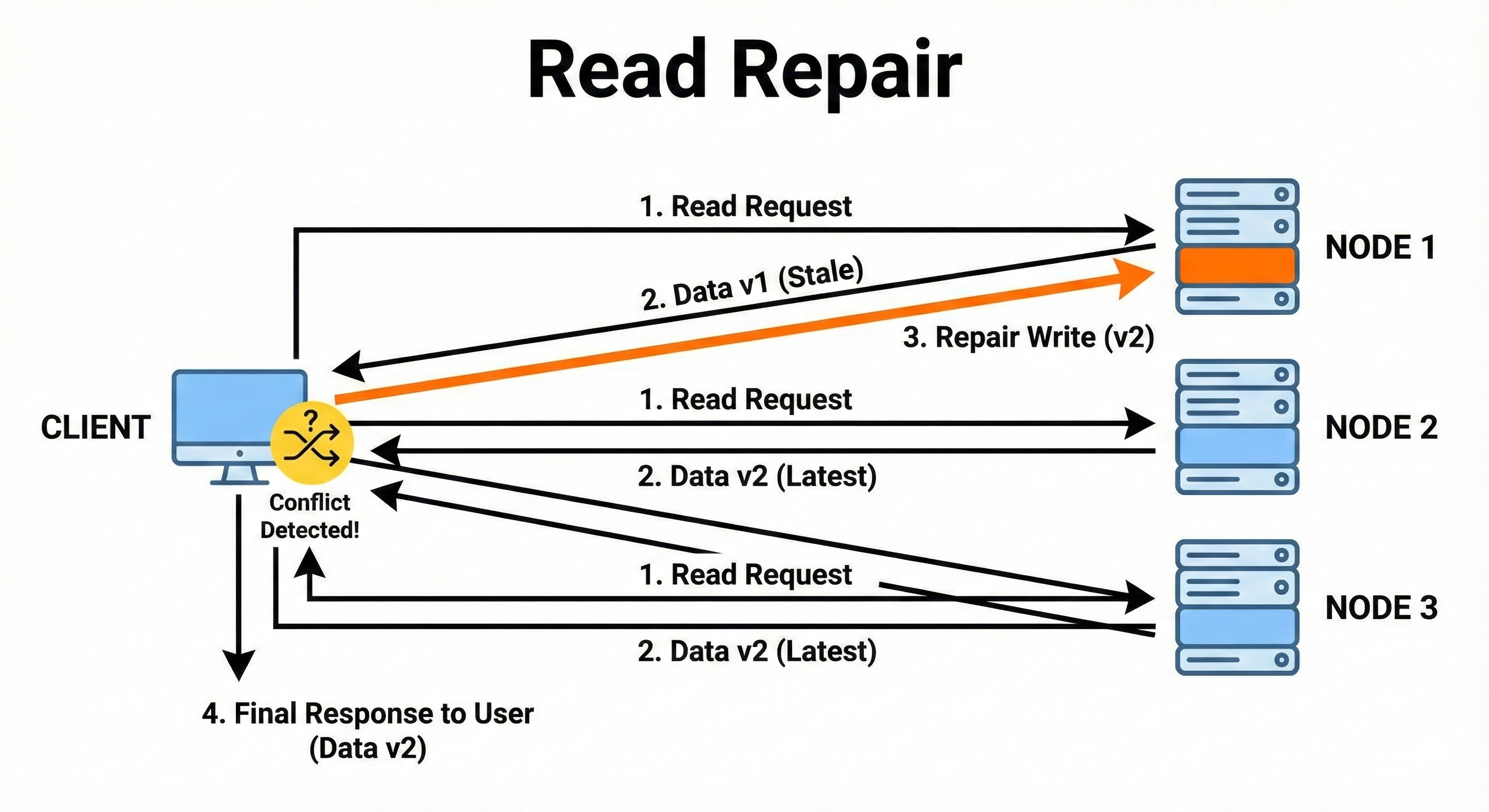
Read repair works best when reads are frequent.
Example
A user fetches their profile and the system finds one replica with an older version.
The correct value is returned to the user, and the outdated replica is silently updated at the same time.
Conclusion
Replication is not a single technique but a collection of strategies that help systems stay durable, fast, and reliable.
Understanding these sixteen concepts gives you the clarity to design large-scale systems, debug real-world issues, and excel in system design interviews.
These ideas form the foundation of modern distributed databases, global applications, and cloud systems used today.