
12 Microservices Architecture Patterns: Service Boundaries, Data Consistency, Resilience, and Migration
The Twelve Microservices Diagrams Every Senior Engineer Should Be Able to Draw, Covering Boundaries, Transactions, Event Patterns, Migration, and Resilience


What This Blog Will Cover
Service and data boundary design
Distributed transactions and consistency
Read, write, and event patterns
Safe migration and routing
Resilience and observability patterns
Microservices have become the default way to build large systems, yet they are also one of the most misunderstood topics in engineering. Splitting a system into many small services sounds simple, but the moment data must stay consistent across them, the difficulty appears.
The hard parts of microservices are rarely about writing a single service. They are about how the services relate, share data, fail, and evolve together.
This is exactly why microservices diagrams reveal real experience so quickly.
A junior engineer can describe what a microservice is.
A senior engineer can draw how a distributed transaction stays consistent across services, how a monolith is safely broken apart, and how one failing service is stopped from taking down the rest. These pictures show a depth of understanding that words alone cannot.
Each microservices pattern solves a specific problem and carries its own trade-offs. Once these patterns are clear, the architecture stops feeling like a tangle of services and starts feeling like a set of deliberate choices.
The engineer who can sketch each one and explain the trade-off behind it can reason about almost any microservices system, even an unfamiliar one.
This guide covers twelve microservices architecture diagrams that, together, capture how modern microservices really work.
For every diagram, there is a short description, a note on when to use it, and the single most important idea it captures.
The goal is to make these patterns simple enough to draw from memory.
A Quick Word on Common Terms
A few words appear throughout this guide, so it helps to define them early.
A service is a small, independent application that owns one part of the system.
A monolith is a single large application that holds all the features together.
Coupling describes how tightly two parts depend on each other, and loose coupling is usually the goal.
Eventual consistency means that data across services becomes consistent over time rather than instantly.
With those in place, the diagrams below flow most naturally as a sequence, although they can be read in any order.
Category 1: Defining Service Boundaries
Diagram 1: Service Decomposition by Bounded Context
This diagram shows a system split into services that match business areas rather than technical layers.
A bounded context is a clear boundary around one area of the business, such as billing or shipping, within which the data and rules stay consistent. Each service owns one bounded context and the data that belongs to it.
The boundaries follow the shape of the business, not the shape of the code.
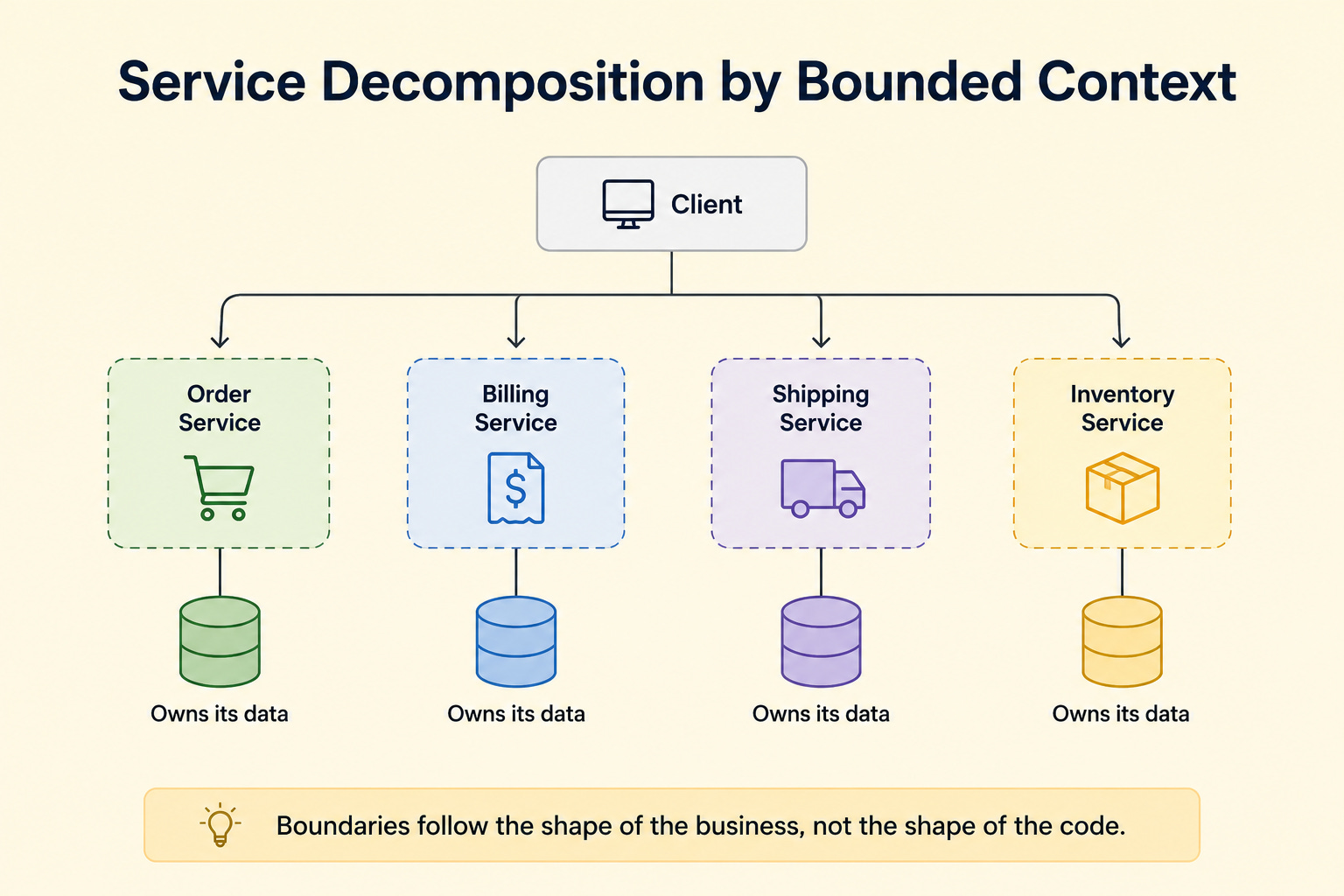
When to use it: This approach fits any system being broken into services, especially when teams want clean ownership and minimal overlap.
The key insight: Splitting by business area keeps related logic and data together inside one service, which reduces the need for services to constantly talk to each other. Splitting by technical layer instead would scatter a single business concept across many services and create heavy coupling.
Diagram 2: Database per Service With the Integration Tax
This diagram shows each service owning its own private database, with no shared database between services.
A service can only reach another service’s data by asking that service, never by reaching directly into its tables.
This independence comes with a cost often called the integration tax, which is the extra work needed to combine data and keep it consistent across services.
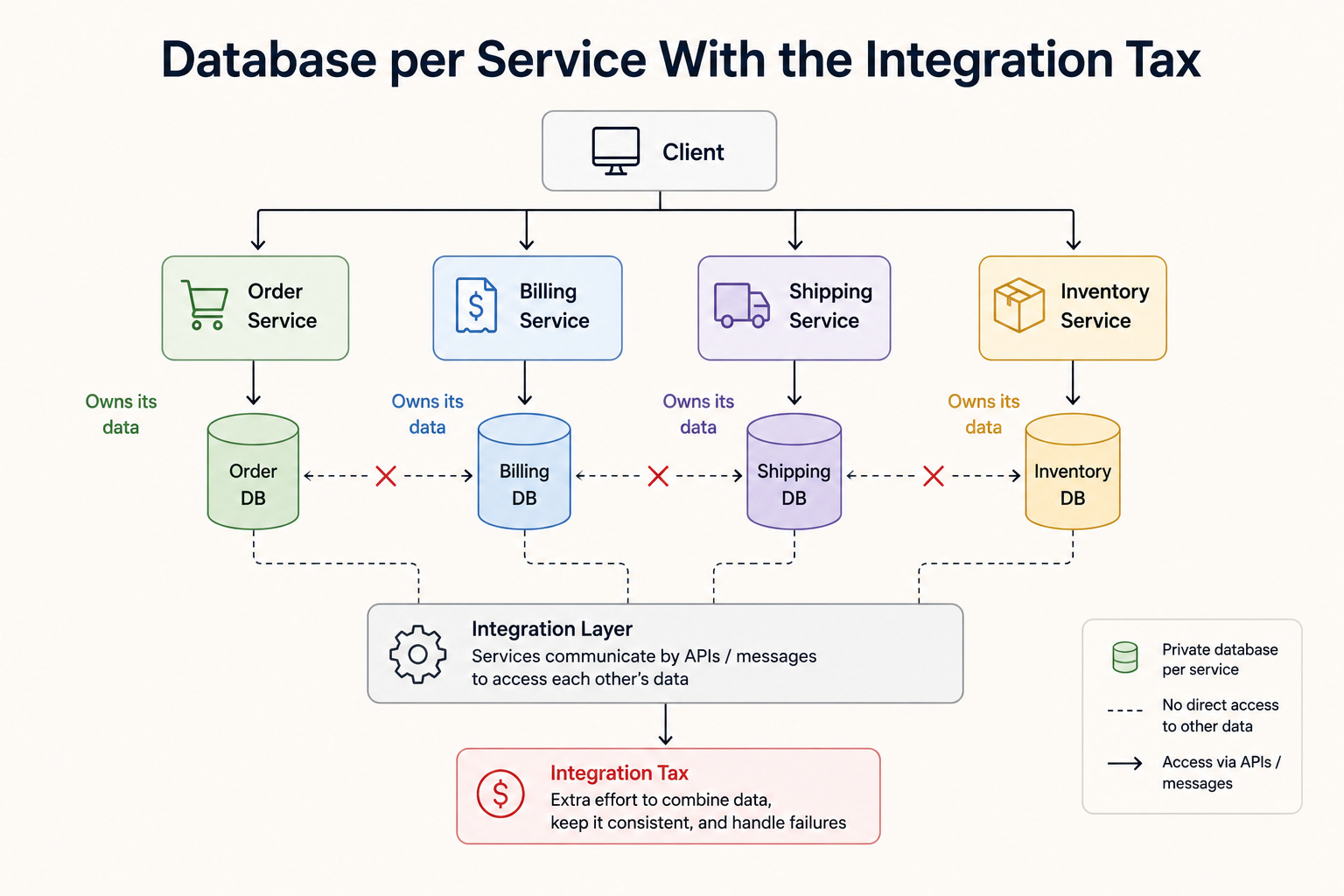
When to use it: Database per service fits systems that need services to scale, deploy, and change independently without stepping on each other.
The key insight: Private databases give true independence, since one service can change its data design without breaking others. The trade-off is the integration tax, because cross-service joins and single all-or-nothing transactions are no longer possible, and the system must rely on APIs, events, and eventual consistency instead.
Category 2: Keeping Data Consistent Across Services
Diagram 3: Saga Choreography
This diagram shows a distributed transaction managed entirely through events, with no central controller. Each service performs its own local step, then publishes an event announcing what it did. Other services listen for that event and react with their own steps.