
12 Distributed Systems Diagrams for Software Engineers
The 12 Core Distributed Systems Diagrams Every Engineer Should Be Able to Draw, Covering Consensus, Replication, Quorums, CRDTs, and Service Mesh Patterns


Distributed systems sit at the heart of almost every modern product.
Once a system grows past a single machine, the questions stop being about clean algorithms and start being about messy realities.
How do many machines agree on a single value?
How does a system keep working when some machines fail?
How does data stay correct when copies live in many places at once?
These questions are the core of senior and staff-level engineering interviews. Candidates who can speak about them with confidence stand out immediately.
Candidates who only know how to draw a generic web architecture quickly hit a ceiling.
The gap between the two usually comes from a single skill, which is the ability to think about distributed systems in clear pictures.
Each distributed systems pattern solves a specific problem and carries its own trade-offs. Once these patterns are clear, the field stops feeling intimidating and starts feeling structured.
The engineer who can sketch each one and explain the trade-off behind it can reason about almost any large-scale system, even one they have never seen before.
This guide covers twelve distributed systems diagrams that, together, handle the distributed parts of any system design question. Each one is explained in plain language.
For every diagram, there is a short description, a note on when to use it, and the single most important idea it captures.
The goal is to make these patterns simple enough to draw from memory.
A Quick Word on Common Terms
A few words appear throughout this guide, so it helps to define them early.
A node is a single machine or process in a distributed system.
A cluster is a group of nodes working together.
Consensus is the process by which nodes agree on a value despite failures and delays.
Consistency is the rule about how synced the data must be across nodes.
With those in place, the diagrams below can be read in any order, although they flow most naturally as a sequence.
Category 1: Consensus and Failure Detection
Diagram 1: Raft Leader Election Step by Step
This diagram shows how a group of nodes choose a single leader. Each node starts as a follower, and if a follower hears nothing from a leader for a while, it becomes a candidate and asks the others for votes.
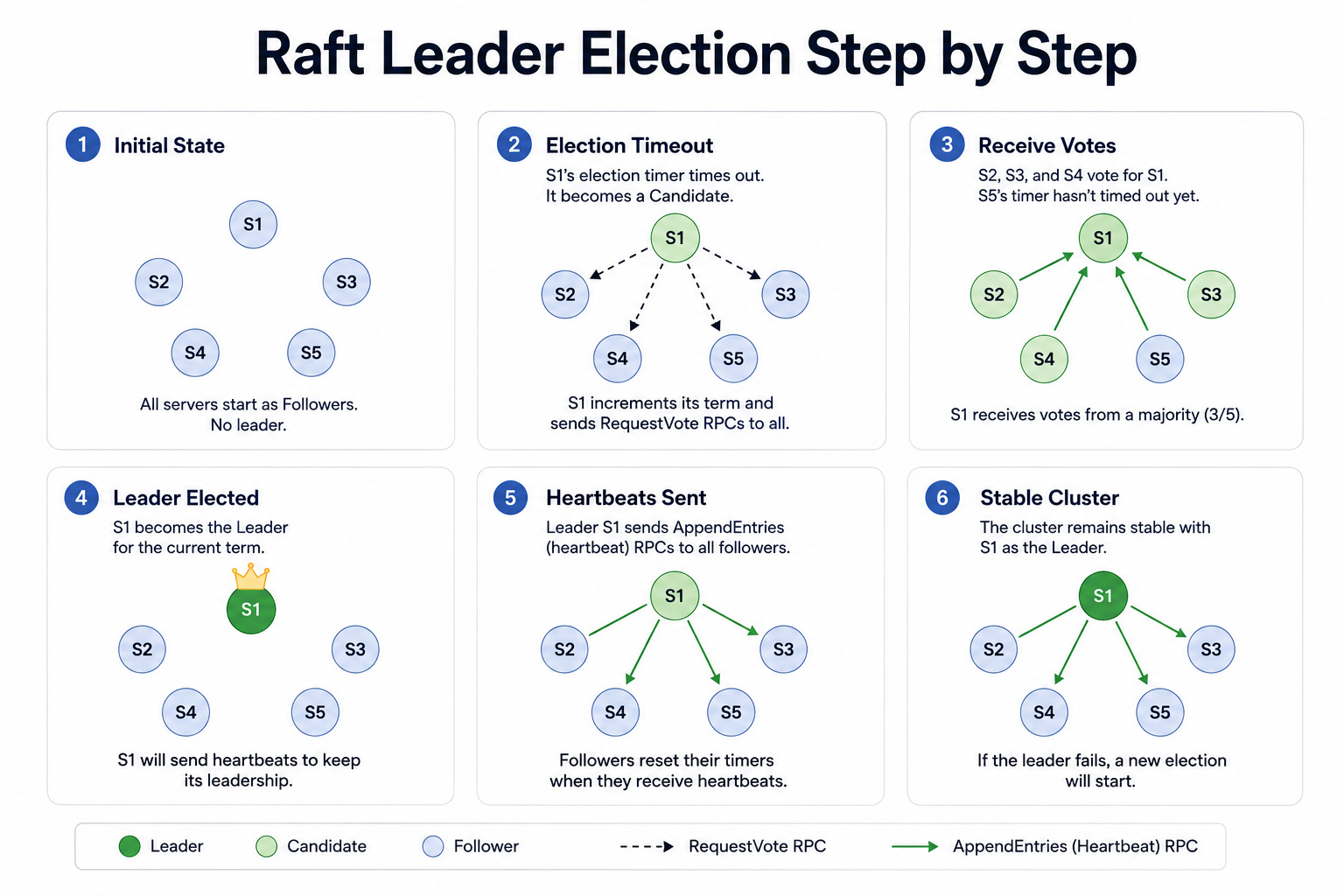
A candidate that collects votes from a majority of nodes becomes the new leader and begins coordinating the cluster.
When to use it: This diagram applies whenever a cluster needs a single point of coordination, such as for ordered writes or distributed locks.
The key insight: A majority vote prevents two leaders from being elected at the same time, even when the network is unreliable. The cluster always has either one leader or none, never two competing leaders making conflicting decisions.
Diagram 2: Heartbeat-Based Failure Detection
This diagram shows nodes sending small messages, called heartbeats, to each other at regular intervals.
When a node stops sending heartbeats for a set amount of time, the other nodes mark it as failed.
The timeout controls how quickly failures are noticed and how often false alarms happen.
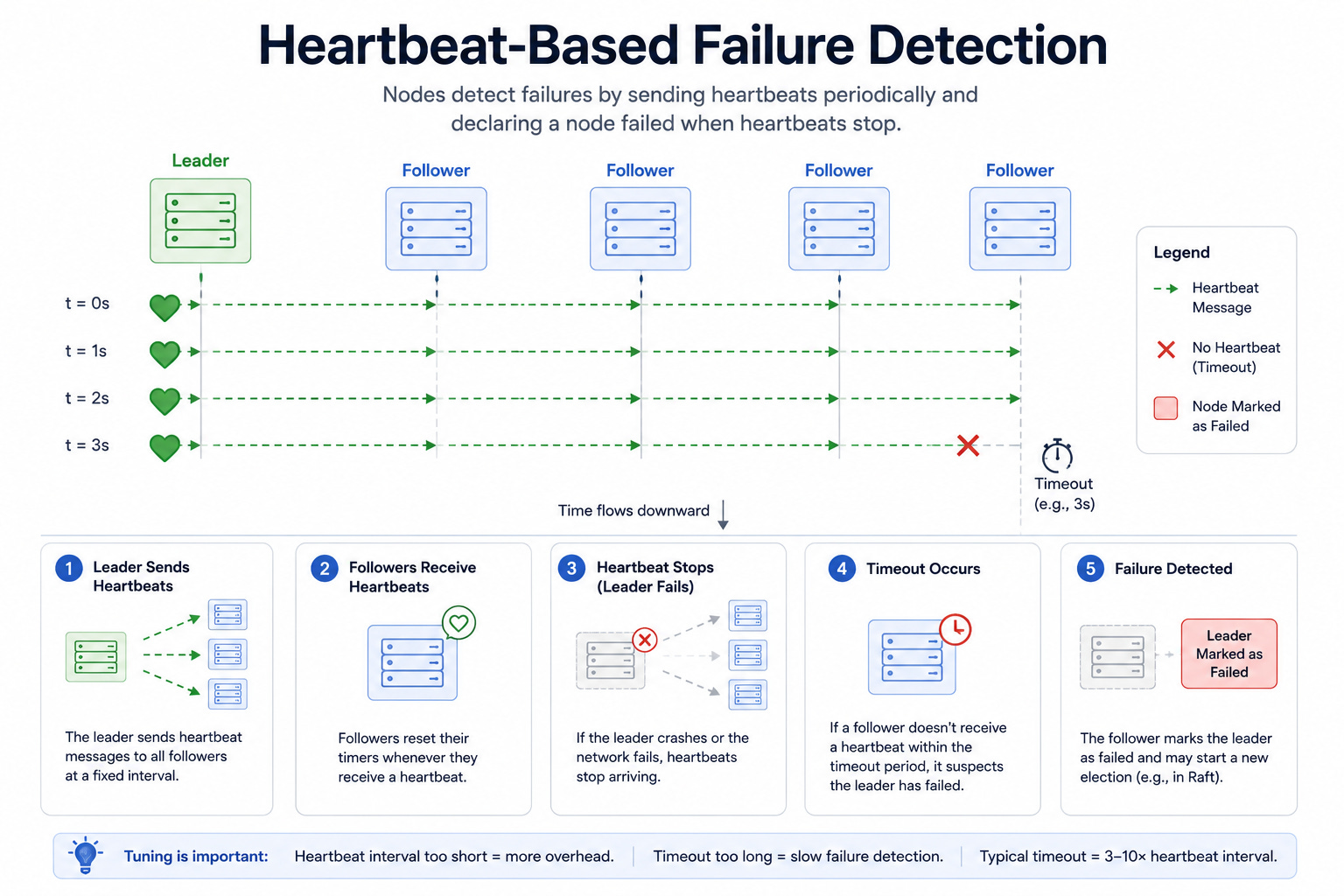
When to use it: Heartbeats fit any cluster where failures must be detected so the system can react, such as leader election or load balancing.
The key insight: Detecting failures is a balance. A short timeout catches problems quickly but flags healthy nodes during brief slowdowns, while a long timeout avoids false alarms but lets the system run blind to real failures longer.
Category 2: Distributed Transactions
Diagram 3: Two-Phase Commit
This diagram shows a coordinator and several participants working together on a single transaction.
In the first phase, the coordinator asks every participant if they are ready to commit, and each one replies yes or no.
In the second phase, the coordinator either tells everyone to commit or tells everyone to roll back.
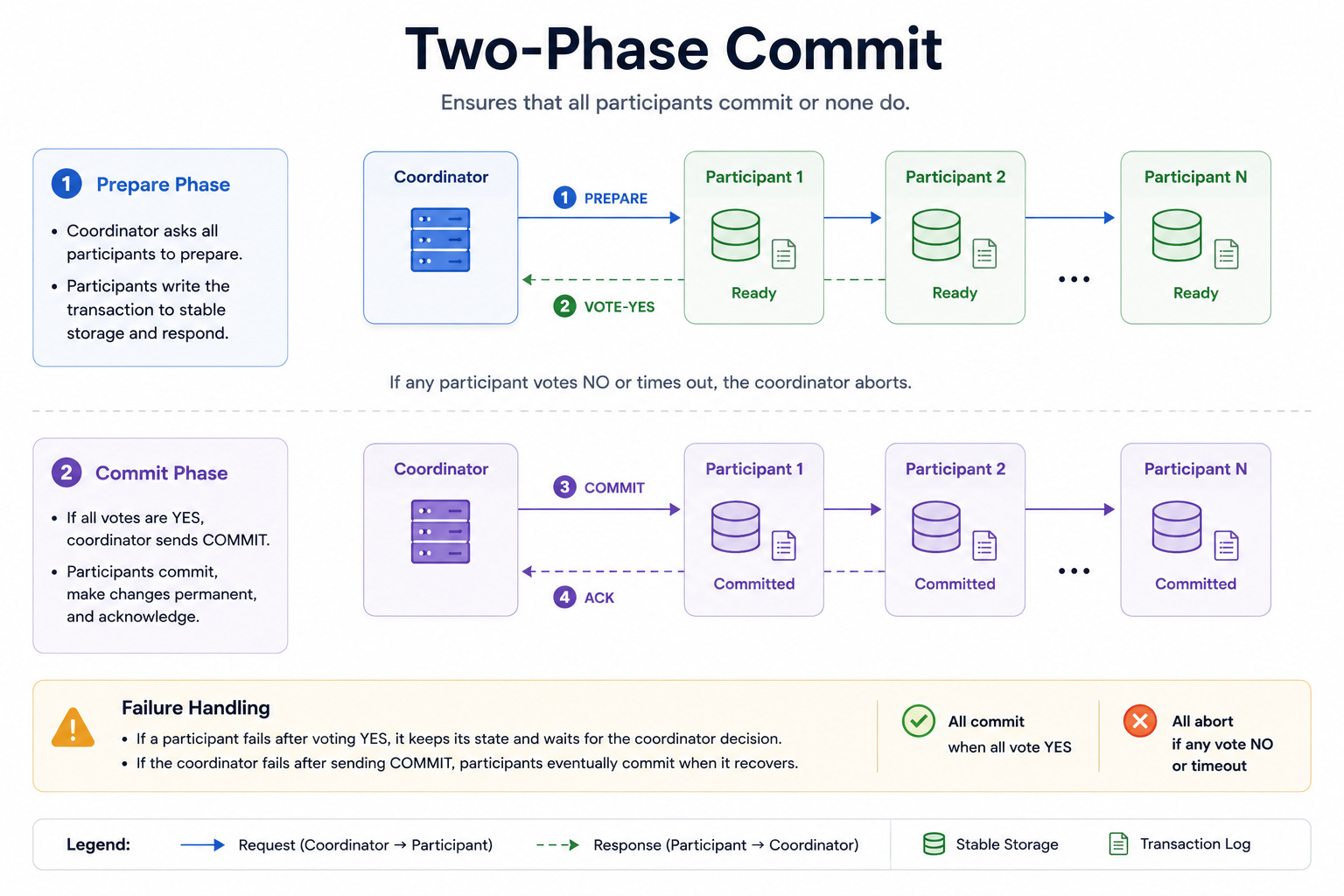
When to use it: Two-phase commit fits cases that need strict consistency across multiple systems, such as moving money between databases that must update together.
The key insight: The two phases guarantee that either all participants commit or none of them do. The cost is that participants must hold locks while waiting, and the whole transaction stalls if the coordinator fails partway through.