
System Design 101: The 10 Core Concepts Every Engineer Needs to Master
Explore 10 crucial system design principles explained simply for beginners preparing for technical engineering interviews in 2026.

Software systems face a massive breaking point when thousands of network requests arrive simultaneously.
A standard server architecture handles minor traffic perfectly fine but collapses under heavy load. The physical hardware runs out of processing power and memory space rapidly.
Databases lock up, network connections drop, and entire applications go offline completely.
System design exists to solve this exact technical bottleneck. It provides the architectural blueprint to distribute heavy computing workloads and keep software online during massive traffic spikes.
Mastering these architectural principles is mandatory for passing technical interviews and building reliable software platforms.
Concept 1: Horizontal and Vertical Scaling
When a software application becomes popular, the underlying physical hardware eventually runs out of computing power.
A single computer can only process a specific number of operations per second.
Engineers must add more processing capacity to prevent the system from crashing completely. Choosing the wrong hardware strategy can lead to permanent growth limits.
Behind the Scenes
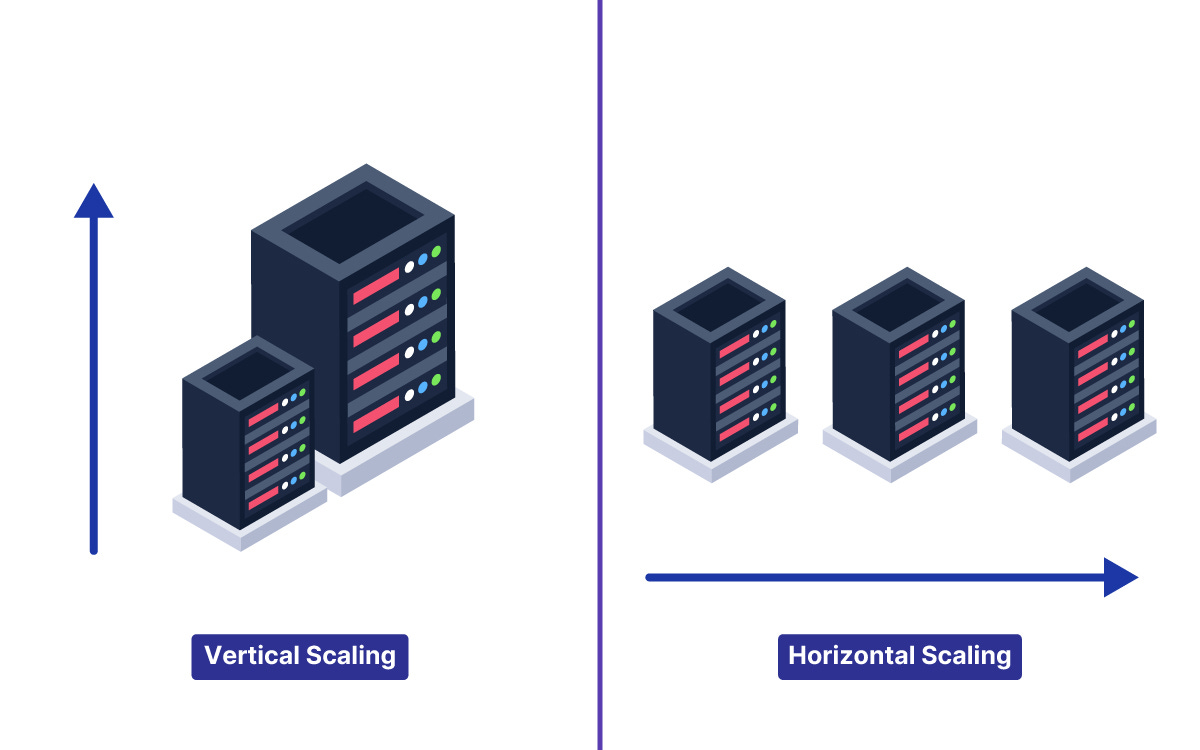
There are two primary ways to add computing capacity to an infrastructure.
Vertical scaling means adding more power to one existing server. Engineers simply install a faster central processing unit or add more memory to that single machine.
However, a single computer has strict physical limits and creates a dangerous single point of failure.
Horizontal scaling solves this physical limitation perfectly. Instead of upgrading one machine, engineers add many standard servers to a shared network.
These independent computers work together to process incoming network traffic as a unified group.
If one computer fails in a horizontally scaled system, the remaining machines continue processing the workload without interruption.
Interviewers expect candidates to default to horizontal scaling when designing large platforms.
Concept 2: Load Balancing
When a system uses horizontal scaling, it operates across dozens of independent servers simultaneously.
The network requires a precise mechanism to decide which specific server should handle each incoming request. If traffic is not actively managed, one server will become overwhelmed while others sit completely idle.
Behind the Scenes
A load balancer is a dedicated routing server that sits directly in front of the main application servers. It intercepts every single incoming network connection before the main application ever sees it.
The load balancer then forwards that request to an available backend server using a mathematical algorithm.
A common method is the round robin technique.
The load balancer sends the first request to server one, the second to server two, and repeats the cycle infinitely. This guarantees an equal distribution of computing work across the entire server cluster.
Additionally, the load balancer continuously sends tiny network pings called health checks to the application servers.
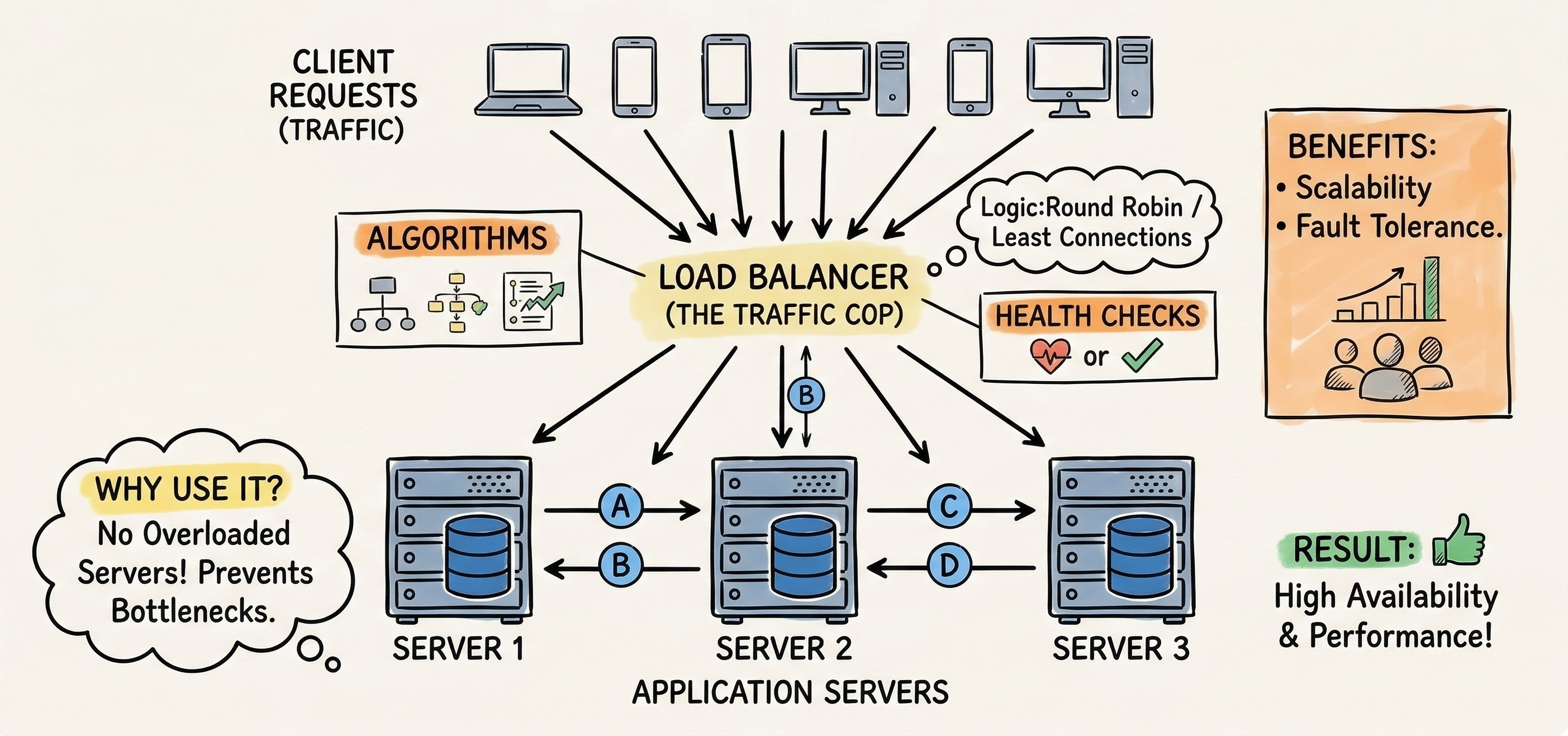
If a server stops responding to these pings, the load balancer automatically stops sending it traffic. It routes all new requests to the remaining healthy servers until the broken machine is repaired.
Concept 3: Caching
Retrieving data from a main database is a remarkably slow technical process. Databases store information safely on physical hard drives, which take mechanical time to read.
When millions of requests ask for the exact same data, reading from the hard drive repeatedly causes severe system delays.
Behind the Scenes
Caching solves this data retrieval delay by storing frequently requested data in fast temporary memory.
Random access memory is exponentially faster to read than a traditional hard drive. When a network request arrives, the software system checks the cache first to see if the data is already there.
If the data exists in the cache, the system returns it instantly. This action skips the slow database reading process entirely and is known as a cache hit.
If the data is missing, a cache miss occurs. The system reads the main database and returns the required information.
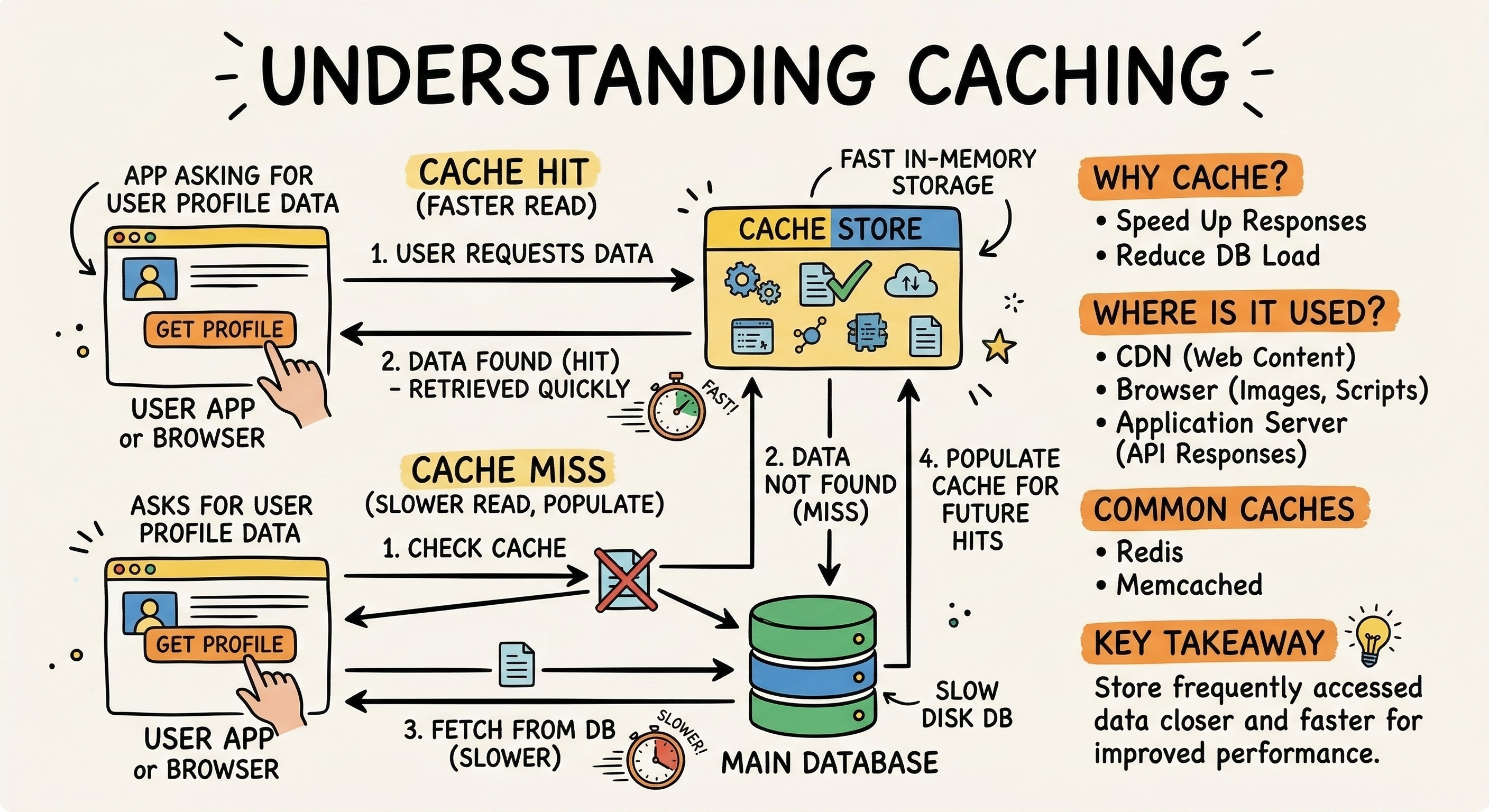
Before finishing the operation, the system saves a copy of that data in the cache for the very next time.
Caching drastically reduces the processing load placed on the primary database hardware. It allows software applications to return data in milliseconds rather than several seconds.
Concept 4: Database Sharding
As a software application accumulates information over time, a single database table can grow to contain billions of rows. Searching through this massive table becomes incredibly slow and consumes excessive computing power.
A single database server simply cannot hold all the data efficiently without slowing down.
Behind the Scenes
Database sharding is the architectural technique of breaking one massive database into several smaller databases. These smaller databases are called shards, and each one lives on its own separate physical server. The software uses a specific piece of data called a shard key to route information accurately.
